一个让AI“听懂人话”的超级模型 —— Transformer。Transformer不仅是技术突破,更是AI理解人类语言的一座里程碑!
1. 引言
首先,让我们快速回顾一下AI、机器学习和深度学习的关系:
- AI:就像造一个智能体,目标是让它像人一样思考。但直接告诉它所有规则几乎不可能,于是有了机器学习。
- 机器学习:让机器通过学习大量数据自己发现规律。就像你给机器看1000张猫图,它就能学会识别猫。
- 深度学习:则是用多层神经网络(类似人脑的神经元)来模拟人脑,让机器能处理更复杂的任务,实现更复杂的学习,比如识别图片中的文字、理解语音中的情绪。
但语言理解一直是个大难题!
人类语言有复杂的结构:比如“我吃梨”和“梨吃我”完全是相反的意思,词的位置决定了含义,这就涉及到语法结构和词序的关系。
那么,我们如何让机器理解这些关系?
今天的故事要从Word2Vec开始,一步步带大家走向Transformer,看看它如何彻底改变自然语言处理的格局!
2. NLP发展历程:从Word2Vec到Transformer
2.1 Word2Vec(2013年):词的“身份证”
- 突破:Word2Vec的核心是将每个词表示为一个固定维度的向量(通常为100到300维),这种向量能够捕捉到词语之间的语义关系。举个例子,Word2Vec将“国王”表示为一个向量$[-0.2, 0.8, 1.1]$,而“女王”可能表示为$[0.1, 0.7, 1.3]$,两者非常相似。通过这样的方式,Word2Vec不仅能捕捉到词语的基本含义,还能理解词语之间的关系,比如“国王 - 男人 + 女人 ≈ 女王”。
- 你可以把词向量(Word Embedding)看作词的“身份证”,它记录了一个词的位置和关系,比如“国王”和“女王”的向量就会很接近,因为它们表示的是同一类角色,但性别不同。
- Skip-gram模型:Word2Vec的训练通过一个叫Skip-gram的模型进行。Skip-gram模型的目标是通过给定一个中心词,预测周围的上下文词。通过最大化这种条件概率,模型最终学会了将相似意义的词映射到相似的向量空间。
-
假设在我们的文本序列中有4个词,[“我”, “爱”, “吃”, “梨”]。每个词都会被随机初始化为一个向量,为了简单起见,我们假设这些词的向量维度为3。初始化后的词向量可能是这样的:
词 向量 (3维) 我 [0.2, 0.1, -0.3] 爱 [-0.1, 0.5, 0.3] 吃 [0.4, -0.6, 0.2] 梨 [-0.3, 0.2, 0.8] - 这些向量是随机初始化的,训练过程中会不断调整这些向量,使得它们能够更好地表示词语之间的关系。
- 假设我们的窗口大小
skip-window=1,中心词为“爱”,那么上下文的词即为:“我”、“吃”。这里的上下文词又被称作“背景词”,对应的窗口称作“背景窗口”。 - Skip-gram能帮我们做的就是,通过中心词“爱”,预测它的上下文词“我”和“吃”。对于每对(中心词,上下文词),模型会计算条件概率,即给定中心词,预测上下文词的概率,核心是通过概率最大化来学习并更新词向量。我们可以通过点积来计算中心词和上下文词的相似度,并通过Softmax函数得到最终的概率:
- 对于“爱”与“我”,计算“爱”向量与“我”向量的点积:
然后用Softmax来处理这个值,得到“爱”与“我”之间的概率。
- 对于“爱”与“吃”,计算“爱”向量与“吃”向量的点积:
同样,用Softmax得到“爱”与“吃”之间的概率。
-
模型会根据这些计算得到的概率来调整每个词的向量。目标是最大化给定“爱”来预测“我”和“吃”的概率。通过反向传播算法,更新每个词的向量。最终通过多次迭代训练,模型会不断调整词向量,以便更好地预测上下文词。随着训练的进行,词向量逐渐会变得更加准确,能够表示词语之间的语义关系。
词 向量 (3维) 我 [0.25, 0.15, -0.35] 爱 [-0.05, 0.45, 0.4] 吃 [0.45, -0.55, 0.25] 梨 [-0.3, 0.25, 0.85] 在这种情况下,“爱”和“吃”的向量会更加接近,而“爱”和“梨”的向量则相对较远,表示它们的语义关系更为紧密。
-
- 通过Skip-gram模型,Word2Vec学习每个词如何与其周围的词产生关联,进而获得这些向量。其中,“爱”与“吃”之间的向量距离变小,因为它们有语义上的关联。而“爱”与“梨”之间的向量距离相对较大,语义关系不如“吃”紧密。最终,经过训练,模型得出的向量不仅代表了词的“形式”,还隐含了它们的“含义”。比如,词向量在高维空间中相似的词语会聚集在一起,表示它们的语义相似。
- 问题:虽然Word2Vec能够捕捉到语义相似度,但它无法理解词序。比如“我爱吃梨”和“梨爱吃我”这两个句子,虽然语义相近,但Word2Vec将它们的向量表示完全相同。因此,它无法处理句子中词语的顺序问题。
2.2 RNN/LSTM:给语言加上“记忆”
- 突破:RNN(循环神经网络)通过引入“记忆”机制,按顺序处理每个词。对于每个词,RNN不仅依赖于当前词的输入,还会考虑前一个词的输出,从而使得模型能够捕捉到时间依赖性(即词语之间的顺序关系)。例如,在句子“我出生在法国,所以我会说___”中,RNN会记住“法国”这一信息,进而预测出“法语”。
- 举个简单的例子:假设你在听一个人讲故事,每次讲到一句话,你会根据前面讲的内容预测接下来可能发生的事情。RNN就是通过不断回顾前面的内容,帮助模型记住整个“故事”的进展。
- 问题:RNN有两个主要问题:
- 无法并行计算:每次只能处理一个词,所以计算速度很慢。如果句子特别长,就更慢了。
- 长句子失忆:随着句子的长度增加,RNN逐渐“忘记”前面的话。例如,在句子“我从小在法国长大,后来去美国读书…”中,RNN可能就记不住“法国”这个信息了。
- LSTM:LSTM(长短期记忆网络)是对RNN的改进,增加了记忆单元,通过门机制来决定是否保留或丢弃某些信息。LSTM的遗忘门、输入门和输出门允许模型在适当的时候保留关键的信息,同时忘记不重要的内容,从而解决了RNN的长句子失忆问题。
- 致命缺点:
- 无法并行计算:RNN和LSTM是顺序处理的,必须一个字一个字地传递信息,导致训练速度非常慢,尤其是当处理长句子时。
- 长句子失忆:即使是LSTM,也难以在处理长句子时保留远距离的信息,特别是当序列长度大于一定值时,模型会逐渐“遗忘”较早的输入信息,导致性能下降。
2.3 注意力机制:选择性关注
-
突破:注意力机制(Attention Mechanism)通过让模型选择性地关注输入中的某些重要部分,提升了模型的表现。具体来说,模型通过计算每个词对其他词的关注程度,并基于这种关注来加权合并信息。也就是说,模型可以选择性地忽略不重要的词,而不是平均地关注句子中的每个词。
注意力机制的核心在于通过计算注意力权重来调整每个输入的“重要性”,然后进行加权平均。一般来说,我们会有三个核心的部分:
- Query(查询向量):通常是我们想要理解的或聚焦的部分。
- Key(键向量):与查询向量相关联的部分。
- Value(值向量):实际的信息或特征,通常是我们最终的输出。
然后我们会基于查询向量去关注其他词,然后结合它们的值进行加权求和。
-
计算方式:
-
输入:Word2Vec 词向量:假设我们已经得到了一个句子的词向量(通过Word2Vec或者其他方式)。这些是已经训练好的词向量,我们将它们作为输入来使用注意力机制进行计算。
词 向量 (3维) 我 [0.25, 0.15, -0.35] 爱 [-0.05, 0.45, 0.4] 吃 [0.45, -0.55, 0.25] 梨 [-0.3, 0.25, 0.85] - 计算相似度(得分):这里我们假设“爱”是查询向量(Query),我们需要计算查询向量“爱”与其他每个词(即“我”,“吃”,“梨”)的相似度(得分),通常通过点积(Dot Product)来衡量相似度。具体来说,我们将查询向量(Query)与每个键向量(Key)做点积:
- Query(“爱”): 向量$[-0.05, 0.45, 0.4]$
- Key 1(“我”): 向量$[0.25, 0.15, -0.35]$
- Key 2(“吃”): 向量$[0.45, -0.55, 0.25]$
- Key 3(“梨”): 向量$[-0.3, 0.25, 0.85]$
计算相似度(点积):
- 得分1(“爱”与“我”):
- 得分2(“爱”与“吃”):
-
得分3(“爱”与“梨”):
\[score(爱,梨)=(−0.05×−0.3)+(0.45×0.25)+(0.4×0.85)=0.015+0.1125+0.34=0.4675\]
-
计算注意力权重:下一步是将这些得分转换为注意力权重。通常我们使用Softmax函数来规范化这些得分,使它们变成一个概率分布,权重和为1。
Softmax的公式为:
\[\text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}}\]其中,$x_i$是每个得分。
对得分进行Softmax处理:
\[\text{Softmax}(-0.085, -0.17, 0.4675) = \left( \frac{e^{-0.085}}{e^{-0.085} + e^{-0.17} + e^{0.4675}}, \frac{e^{-0.17}}{e^{-0.085} + e^{-0.17} + e^{0.4675}}, \frac{e^{0.4675}}{e^{-0.085} + e^{-0.17} + e^{0.4675}} \right)\]我们可以计算出具体的权重(简化过程):
- 权重1(“我”) ≈ 0.28
- 权重2(“吃”) ≈ 0.22
- 权重3(“梨”) ≈ 0.50
-
加权求和(输出):接下来,使用这些注意力权重对每个词的值(Value)进行加权求和,得到最终的输出向量。假设每个词的值向量(Value)与它们的词向量相同(在实际应用中,值向量可能会经过转换,或者在某些情况下与键向量相同)。
词 向量 (3维) 我 [0.25, 0.15, -0.35] 吃 [0.45, -0.55, 0.25] 梨 [-0.3, 0.25, 0.85] 现在使用计算出的权重对这些值向量进行加权求和:
\[\text{输出向量} = (0.28 \times [0.25, 0.15, -0.35]) + (0.22 \times [0.45, -0.55, 0.25]) + (0.50 \times [-0.3, 0.25, 0.85])\]所以,最终输出的向量为:$[0.019, 0.046, 0.382]$。
-
目标和训练优化:在这个例子中,目标是根据“爱”这个查询词,结合其他词(“我”,“吃”,“梨”)的加权组合,得到一个能够表示“爱”在特定上下文中意义的输出向量。为了达到这个目标,我们需要通过训练来优化模型的权重(即查询、键和值向量),使得最终的输出能够最大化任务目标(如分类、生成、翻译等)的准确性。
训练优化过程:
- 目标函数: 在训练过程中,模型的输出会与真实标签(如翻译任务中的目标词)进行比较,计算损失(loss)。损失函数可以是均方误差(MSE)、交叉熵等,根据任务的不同而不同。
- 反向传播: 通过反向传播算法,损失将反向传递至模型的各个参数(包括查询向量、键向量和值向量),并根据损失的梯度信息调整参数。这样,在每次训练迭代中,模型的注意力权重会逐渐优化,最终使得模型能够在特定任务中更准确地聚焦于重要信息,从而提高任务的性能。
-
2.4 Transformer(2017年):抛弃“顺序”,拥抱“全局”
- 核心理念:2017年,Vaswani等人提出的Transformer架构通过完全抛弃顺序计算,让每个词能够与其他所有词直接联系。这意味着Transformer不再使用RNN的“顺序计算”方式,而是采用了全局交互的方式,让所有词的关系可以同时被考虑。这种设计大大提高了计算效率,并能捕捉到更为复杂的依赖关系。
- 三大优势:
- 并行计算:由于所有词的计算是独立的,Transformer能够同时处理所有词,因此训练速度比RNN快了数十倍。尤其对于长文本,Transformer表现尤为突出。
- 超长记忆:传统RNN在处理长句子时会失去远距离的信息,而Transformer通过全局注意力机制使得模型能够直接看到任意两个词之间的关系,无论它们的距离多远。每个词与其他所有词都有直接的联系,从而有效解决了长距离依赖的问题。
- 灵活扩展:Transformer的架构设计非常灵活,通过堆叠多个编码器(Encoder)和解码器(Decoder)层,能够更好地提取文本中的高层次特征。每一层都能通过注意力机制聚焦于不同的词对,从而有效提取不同层次的语义信息。
2.5 BERT(2018年):双向理解的王者
- 突破:BERT(Bidirectional Encoder Representations from Transformers)是基于Transformer架构的一个深度预训练模型,主要依赖于Transformer的Encoder部分。与传统的单向语言模型不同,BERT采用了双向训练,能够同时考虑一个词左边和右边的上下文信息(前后文),这使得它对文本的理解更加准确。
- 完形填空训练(Masked Language Model):BERT的训练过程采用了完形填空的方式,即在输入句子中随机屏蔽掉一些词(如“我爱吃[MASK]”),模型通过上下文推测出被屏蔽的词(例如,“梨”)。这种训练方式帮助BERT更好地理解句子的上下文关系,而不仅仅是顺序上的依赖。
- 关键点:BERT不同于传统的左到右或右到左的语言模型,它通过双向的上下文来捕捉更丰富的语义信息。这使得BERT在各种NLP任务中表现得非常优秀,比如问答、情感分析、文本分类等。
- 应用优势:
- 由于BERT是一个预训练模型,它可以通过少量的微调(Fine-tuning)适应不同的下游任务。因此,BERT不仅可以应用于机器翻译,还可以在文本分类、命名实体识别、文本生成等多种任务中取得突破。
从Word2Vec到BERT,NLP的技术发展经历了从静态词向量到动态上下文理解的革命。而Transformer架构的提出,标志着NLP技术的重大飞跃,不仅使得模型能够更好地捕捉上下文信息,而且通过并行计算和超长记忆使得训练速度得到了极大的提升。BERT则通过双向理解进一步提高了模型的语义捕捉能力,成为了现代NLP任务的标杆。
3. Transformer的架构与原理
Transformer 是一种基于自注意力机制(Self-Attention)的深度神经网络,它抛弃了传统 RNN 的递归结构,允许所有输入词并行计算,并且能有效地捕捉长距离依赖关系。它最早由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。
Transformer 主要由编码器(Encoder)和解码器(Decoder)组成,每个部分都包含多个相同的子层,核心模块包括:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed-Forward Network, FFN)
- 残差连接(Residual Connection)
- 层归一化(Layer Normalization)
- 位置编码(Positional Encoding)
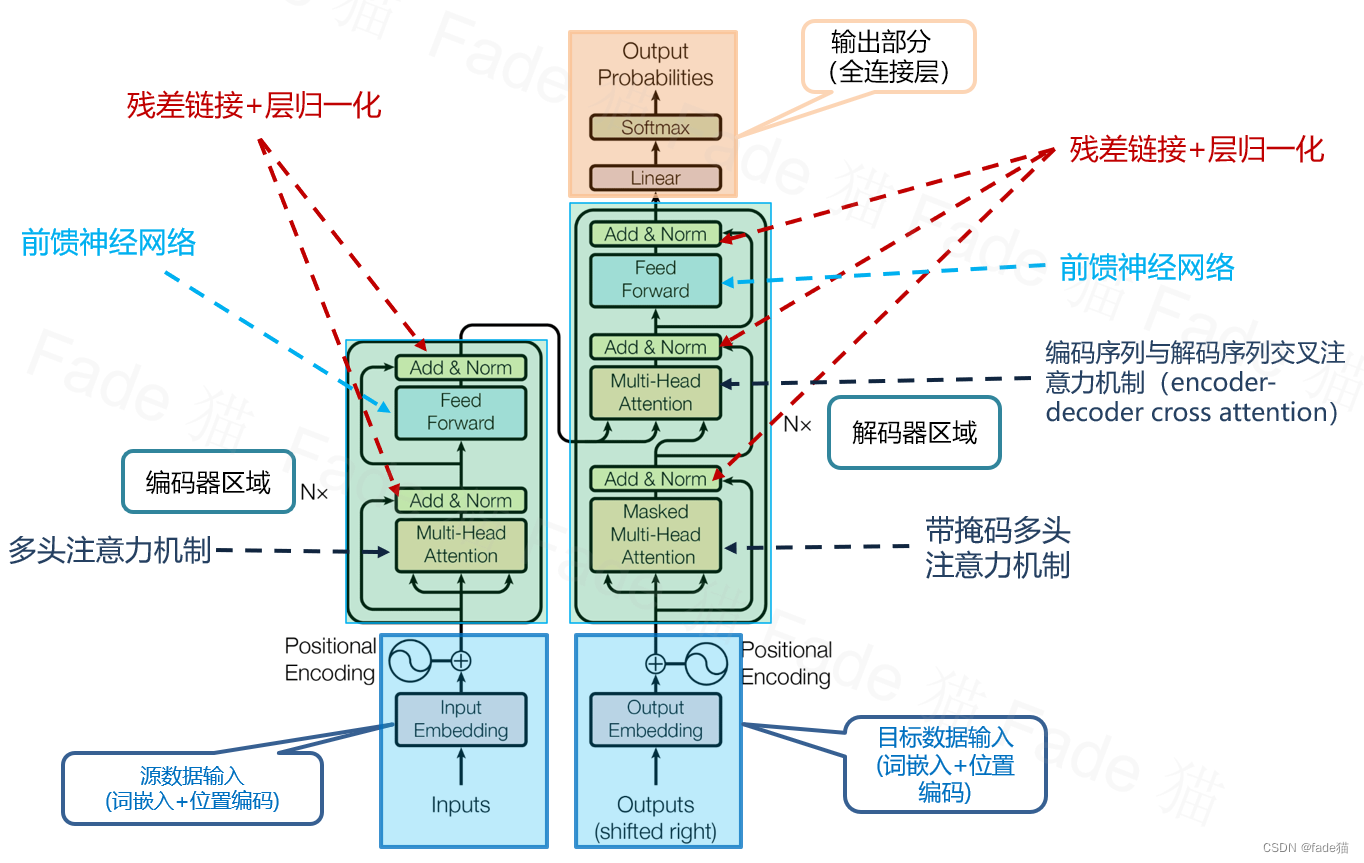
3.1 整体结构:Encoder和Decoder的“流水线”
Transformer 的架构由 N 层 Encoder + N 层 Decoder 组成,其中:
- Encoder:负责理解输入(比如中文句子)
- 输入一个序列(如句子),对每个词进行编码,提取其上下文信息。
- 由 自注意力机制(Self-Attention)和 前馈网络(FFN)组成,每个词的表示向量可以根据所有输入词的信息进行更新。
- Decoder:负责生成输出(比如英文翻译)。
- 负责生成输出,比如从中文翻译到英文时,Decoder 逐步生成英文句子。
- 由 Masked 自注意力(Masked Self-Attention)、交互注意力(Encoder-Decoder Attention) 和 前馈网络(FFN) 组成。
- Masked Attention 确保生成时不会“偷看”未来的词,避免数据泄露(Data Leakage)。
- 交互 Attention 使解码器能够利用编码器的输出,以生成更符合上下文的翻译或文本。
- 核心模块:Self-Attention(自注意力)、前馈网络、残差连接。
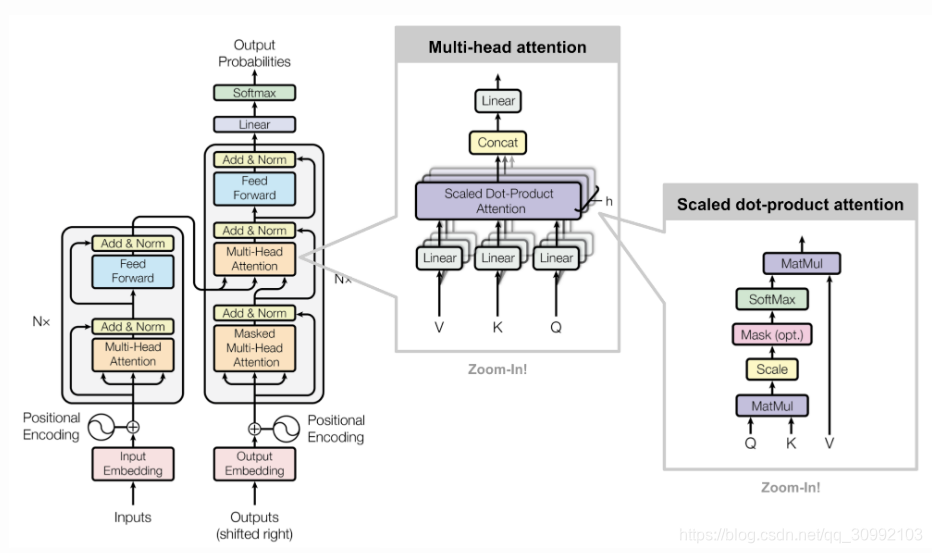
3.2 Self-Attention:让词与词直接“对话”
- 问题:如何让每个词知道其他词的重要性?
- 传统 RNN 处理长文本时,前面的信息难以被后面的词记住,而 Self-Attention 让每个词都能看到整个输入序列,并计算自己与所有其他词的相关性。
-
公式:
\[注意力分数 = Softmax(\frac{Q·K^T}{\sqrt{d_k}})\] \[输出 = 分数矩阵 \cdot V\] - 直观解释:
- Q(Query):当前词的问题,比如“我是谁?”
- K(Key):其他词的答案索引,比如“苹果是水果”。
- V(Value):其他词的真实信息,比如“苹果=红色、甜、水果”。
- 计算过程:当前词通过提问(Q)与其他词的答案(K)匹配,找到最相关的信息(V)并整合。
- 输入:Word2Vec 词向量
词 向量 (3维) 我 [0.25, 0.15, -0.35] 爱 [-0.05, 0.45, 0.4] 吃 [0.45, -0.55, 0.25] 梨 [-0.3, 0.25, 0.85] -
映射到查询(Query)、键(Key)、值(Value)
在标准的 Scaled Dot-Product Attention 中,词向量会被分别映射到 查询(Query)、键(Key) 和 值(Value)。通常,映射是通过将输入词向量与不同的权重矩阵相乘来实现的。
假设我们有权重矩阵 $W_Q$, $W_K$, 和 $W_V$,分别用于将输入词向量转换为查询、键和值。
- 权重矩阵:
- $W_Q$: 用来生成查询的权重矩阵,维度为 $3×3$。
- $W_K$: 用来生成键的权重矩阵,维度为 $3×3$。
- $W_V$: 用来生成值的权重矩阵,维度为 $3×3$。
这些权重矩阵是通过训练学到的(例如在Transformer的训练过程中),我们假设它们已经给定了。
- 假设:
-
计算 Query、Key、Value
我们将每个词的向量分别与 $W_Q$, $W_K$, $W_V$ 相乘,得到查询、键和值:
对于词 “我”,其向量为 :$[0.25,0.15,−0.35]$
- 查询(Query):
- 键(Key):
- 值(Value):
- 权重矩阵:
-
计算点积相似度(Attention Scores)
接下来,我们计算查询(Query)与每个键(Key)之间的点积。我们假设我们想计算查询 “爱”($Q_爱$)与键 “我”($K_我$)的相似度。
- 假设 $Q_爱$ 和 $K_我$ 的向量已经计算好,它们分别是:
- 点积计算公式为:
-
应用 Softmax 获得注意力权重
对所有词的查询和键计算的点积相似度进行 softmax 操作,得到注意力权重。这些权重表示查询与各个键之间的相关性,通常用来加权计算最终的值。
\[\text{Attention Weight} = \text{Softmax}(\text{sim}(Q, K))\]假设有三个词 “我”、“爱” 和 “吃”,我们将它们的相似度值进行 softmax 计算,以获得每个词的权重。
-
加权求和得到最终的表示
最后,通过将注意力权重与对应的值(Value)向量加权求和,得到最终的表示:
\[\text{Output} = \sum_i \text{Attention Weight}_i \times V_i\]这样,经过多个注意力头的计算,就得到了每个词的最终表示。
- 为什么要除以$\sqrt{d_k}$?
- 在计算$Q \cdot K^T$ 时,随着向量维度$d_k$增大,点积的数值范围会扩大,导致 Softmax 变得极端(梯度消失)。为了保持稳定性,论文采用了缩放点积注意力(Scaled Dot-Product Attention)
3.3 多头注意力:多个“专家”会诊
- 比喻:8个专家分别从不同角度分析同一句话,比如语法、情感、逻辑。
- 问题:为什么要多个注意力头(Multi-Head Attention)?
- Self-Attention 计算出了一种“相关性”,但只用一个头(单一注意力机制)可能会忽略不同层次的信息。
- 多头注意力机制是在自注意力机制的基础上扩展而来的,它的核心思想是:不止使用一个查询-键-值计算,而是用多个不同的查询-键-值计算多个注意力头,然后把它们拼接在一起。
- 这样,每个注意力头可以关注输入序列中的不同方面的关系。例如,一个头可能专注于主谓关系,另一个头可能关注形容词修饰,再一个头可能关注动词和宾语的关系。
-
伪代码:
# 输入x是词向量矩阵,形状为 [句子长度, 向量维度] def multi_head_attention(x, num_heads=8): # 把x切分成8份,每份交给一个“专家” heads = [] for i in range(num_heads): q = transform_q(x[:, i]) # 第i个专家的Q k = transform_k(x[:, i]) # 第i个专家的K v = transform_v(x[:, i]) # 第i个专家的V head = compute_attention(q, k, v) # 计算单个头的注意力 heads.append(head) # 把8个结果拼起来 return concatenate(heads)- 多个注意力头(Attention Heads)并行计算,每个头都会学习不同的关注模式。例如:
- 一个头可能学习句子中的主谓关系(”我” 和 “吃”)。
- 另一个头可能学习修饰关系(”吃” 和 “梨”)。
- 还有一个头可能学习时态和结构(”爱” 和 “吃”)。
- 这些不同头的结果最终会拼接(Concat)在一起,然后经过一个线性变换,形成最终的词表示。
- 多个注意力头(Attention Heads)并行计算,每个头都会学习不同的关注模式。例如:
3.4 位置编码:给词加上“坐标”
- 问题:Transformer没有顺序,如何区分“猫抓老鼠”和“老鼠抓猫”?
- 解决方案:给每个词的位置编码一个独特的“坐标”。
- 公式:
- 直观解释:
- 不同位置的词通过不同频率的正弦波组合,形成独一无二的“位置编码”。
- 模型通过这个编码学习词序关系。
3.5 残差连接与LayerNorm:训练稳定的关键
- 残差连接:每层的输出 = 输入 + 本层计算结果。
- LayerNorm:对每层的输出做标准化,让数值稳定(避免某些值过大或过小)。
这样可以:
- 防止梯度消失(梯度可以直接流向底层)。
- 加速训练(模型更容易收敛)。
- 提高稳定性(不会丢失重要的原始信息)。
3.6 Encoder与Decoder的协作
- Encoder:通过多层自注意力,将输入转换为富含上下文信息的向量。
- Decoder:
- Masked Attention:生成时只能看前面的词,不能看到未来信息(避免信息泄露)。
- Masked Attention(掩码注意力)是一种在注意力机制(Attention)中添加掩码(Mask)的变体,主要用于防止某些信息被提前访问,确保模型的训练符合任务要求。
-
Masked Attention的数学表示
\[\text{Attention}(Q, K, V) = \text{Softmax} \left(\frac{QK^T}{\sqrt{d_k}} + M \right) V\]其中:
- Q(Query):查询向量(来自当前生成的部分)。
- K(Key):键向量(来自输入序列)。
- V(Value):值向量(提供信息)。
- M(Mask):掩码矩阵,通常包含非常大的负数(如-∞),用于屏蔽掉不该被关注的部分。
-
假设我们有一个句子:我 喜欢 机器学习
在 Transformer 训练过程中,解码器(Decoder)在预测时应该逐步生成句子:
- 预测第一个词:”我”
- 预测第二个词:”喜欢”(但不能提前看到“机器学习”)
- 预测第三个词:”机器”(但不能看到“学习”)
- 预测第四个词:”学习”
-
掩码矩阵示例
对于一个长度为4的序列:
\[M = \begin{bmatrix} 0 & -\infty & -\infty & -\infty \\ 0 & 0 & -\infty & -\infty \\ 0 & 0 & 0 & -\infty \\ 0 & 0 & 0 & 0 \end{bmatrix}\]- 第一行:第一个词(”我”)只能关注自己。
- 第二行:第二个词(”喜欢”)只能看到自己和前面的词(”我”)。
- 第三行:第三个词(”机器”)只能看到”我”和”喜欢”。
- 第四行:第四个词(”学习”)可以看到”我”、”喜欢”、”机器”,但不能看到未来的词。
- 这个掩码矩阵在计算 Softmax 之前 被加到注意力分数上,确保未来的词位置不会被关注。由于Softmax 遇到 -∞ 时会变成 0,所以模型就无法关注被遮挡的部分。
- 交互Attention:关注编码器的输出,让 Decoder 结合 Encoder 的信息,生成更准确的文本。
- Masked Attention:生成时只能看前面的词,不能看到未来信息(避免信息泄露)。
4. BERT与GPT:Transformer的实际应用
4.1 BERT:双向学霸
- 训练任务:
- 随机遮住15%的词,让模型猜(如“我爱吃[MASK]” → “苹果”)。
- 判断两个句子是否相邻。
- 应用场景:情感分析、问答系统(比如客服机器人)。
4.2 GPT:故事大王
- 训练任务:预测下一个词(如“天空是蓝色的,云朵是___” → “白色”)。
- 特点:生成连贯长文本(比如写小说、编代码)。
4.3 BERT vs. GPT:核心区别
| 对比项 | BERT (双向学霸) | GPT (故事大王) |
|---|---|---|
| 核心架构 | Transformer Encoder | Transformer Decoder |
| 训练目标 | Masked Language Model(MLM) + Next Sentence Prediction(NSP) | 自回归语言模型(Auto-Regressive) |
| 数据处理 | 随机遮盖15%的词,让模型预测 | 给定前面的词,预测下一个词 |
| 语言建模方向 | 双向建模(能看到左+右的词) | 单向建模(只能看到前面的词) |
| 适用任务 | 问答、阅读理解、情感分析、文本分类 | 文本生成、代码生成、文章续写、对话 |
| 缺点 | 不能用于生成任务,输入不能扩展 | 上下文理解能力比 BERT 差,不能看未来的词 |
| 应用场景 | 搜索引擎、问答系统、文本分类 | ChatGPT、AI 写作、自动补全 |
5. 总结与未来
Transformer为什么伟大?
- 全局视野:每个词都能直接“看到”所有其他词,彻底解决长距离依赖。
- 并行计算:训练速度碾压RNN,让超大模型成为可能。
未来方向:
- 多模态:Transformer处理图像、语音(如CLIP模型图文互搜)。
- 高效化:压缩模型大小,提升推理速度(适合手机运行)。
- 通用AI基石:DeepSeek、ChatGPT已展现惊人潜力!
Transformer不仅是NLP的革命,更是通向通用AI的关键一步!