这是笔者在github上开源的一个小项目,目前4颗⭐,链接:Plant Diseases Recognition,在此分享给大家,当然,还有可以优化的地方,欢迎讨论!
任务介绍
近年来,深度学习凭借其强大的自动特征提取能力,在农业研究领域取得了重要突破。其中,植物病虫害的精准分类对于提高农作物的质量和产量,以及减少化学农药(如杀菌剂、除草剂)的不当使用至关重要。
植物叶子病虫害识别任务旨在利用深度学习方法,特别是卷积神经网络(CNN),对植物叶片的健康状况进行自动检测和分类。研究通常基于公开可用的数据集,如 PlantVillage,该数据集包含健康叶片与受病害侵袭叶片的高质量图像。通过在该数据集上训练 CNN 模型,可以实现对不同作物病害的高效识别。
作物病虫害是全球粮食安全的重大威胁,尤其是在基础设施欠缺的地区,病害的快速诊断仍然是一个挑战。然而,随着智能手机的普及和计算机视觉领域的快速发展,深度学习技术为移动端的农作物病害检测提供了新的可能性。研究人员利用受控环境下采集的 54,306 张健康与病害叶片图像,训练深度卷积神经网络,以 识别 14 种作物和 26 种不同病害(或健康状态),从而实现智能化、便捷的病害检测方案。这一技术的发展不仅有助于提升农业生产效率,还能有效减少农药滥用,促进可持续农业的发展。
PlantVillage数据集
PlantVillage 数据集是一个广泛用于植物病虫害识别研究的公开数据集,包含 54,306 张植物叶片图像,并标注有 38 个类别标签。这些类别以 “作物 - 疾病” 的格式表示,例如 “苹果 - 黑星病”,用于精确识别不同作物的病害类型。在数据集中,54,306 张图像实际上对应 41,112 片叶子,其中部分叶片具有多个不同角度或光照条件下的拍摄图像,以增强模型的泛化能力。
在实验过程中,为了适配深度学习模型,首先需要将图像统一调整为 256×256 像素,然后进行模型构建、优化和预测。此外,实验中会生成三种不同格式的 PlantVillage 数据集,以探索数据预处理对模型性能的影响:
- 彩色图像(RGB):保留原始数据集的完整色彩信息,直接用于训练。
- 灰度图像(Grayscale):转换为单通道灰度图,以减少计算复杂度,并测试颜色信息对分类性能的影响。
- 背景去除(Masked Images):采用蒙版技术移除背景,仅保留叶片部分,以提高模型对病害特征的关注度,并优化分割任务的训练效果。
PlantVillage 数据集的多样性和预处理方法,使其成为深度学习领域植物病害识别任务的重要基准数据集,为智能农业和农作物病害检测提供了可靠的数据支持。
感受野
在计算机视觉领域,感受野(Receptive Field) 用于描述神经网络内部不同位置的神经元在 原始图像上的感知范围。由于 卷积神经网络(CNN) 的卷积层和池化层采用 局部连接 方式,每个神经元只能接收来自上一层局部区域的信息,而无法直接获取整幅图像的全局信息。因此,感受野的大小决定了神经元对图像内容的感知程度:
- 较小的感受野:神经元只能捕捉局部细节信息,如纹理、边缘等低级特征。
- 较大的感受野:神经元能够感知更广范围的上下文信息,提取更高级的语义特征。
感受野的大小可以用来衡量网络不同层次的特征抽象程度。随着网络的加深,感受野逐步扩大,使得后续层的神经元能够整合更丰富的图像信息。 由于图像是二维的,感受野通常表现为 正方形区域,并用边长来描述其大小。在 CNN 设计中,感受野的扩展方式 主要依赖 卷积核大小、步长、池化层、网络深度 等因素。合理调整这些参数可以有效扩大感受野,使神经网络能够更好地捕捉全局信息,从而提升对目标特征的理解能力。
代码
1. 生成训练和验证数据(data_generator.py)
import cv2
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import img_to_array
import os
import tensorflow as tf
class DataGenerator:
def __init__(self, config):
self.config = config
self.train_generator = None
self.valid_generator = None
def create_generators(self):
"""创建内存优化的数据生成器"""
# 训练数据增强
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest',
validation_split=self.config.VALIDATION_SPLIT
)
# 验证数据只需要缩放
valid_datagen = ImageDataGenerator(
rescale=1./255,
validation_split=self.config.VALIDATION_SPLIT
)
# 创建训练数据生成器
self.train_generator = train_datagen.flow_from_directory(
self.config.DATA_DIR,
target_size=self.config.IMG_SIZE,
batch_size=self.config.BATCH_SIZE,
class_mode='categorical',
subset='training',
shuffle=True
)
# 创建验证数据生成器
self.valid_generator = valid_datagen.flow_from_directory(
self.config.DATA_DIR,
target_size=self.config.IMG_SIZE,
batch_size=self.config.BATCH_SIZE,
class_mode='categorical',
subset='validation',
shuffle=False
)
return self.train_generator, self.valid_generator
def _create_tf_dataset(self, generator):
"""创建tf.data.Dataset以优化内存使用"""
return tf.data.Dataset.from_generator(
lambda: generator,
output_signature=(
tf.TensorSpec(shape=(None, *self.config.IMG_SIZE, 3), dtype=tf.float32),
tf.TensorSpec(shape=(None, generator.num_classes), dtype=tf.float32)
)
).prefetch(tf.data.AUTOTUNE)
这段代码定义了一个DataGenerator类,用于生成训练和验证数据,优化内存使用并进行数据增强。其主要作用是:
- 初始化: DataGenerator类初始化时接收一个配置对象config,该对象包含数据路径、批大小、图像尺寸等参数。
- create_generators方法:
- 创建了两个ImageDataGenerator对象,分别用于训练集和验证集。训练集生成器进行数据增强(旋转、平移、剪切、缩放、水平翻转等),验证集生成器只进行图像归一化(缩放)。
- flow_from_directory方法从指定的数据目录(DATA_DIR)加载图像数据,调整图像大小,按照批量大小分批返回数据,并且按分类进行标签。
- 数据集根据VALIDATION_SPLIT分为训练集和验证集。
- _create_tf_dataset方法:将数据生成器(train_generator或valid_generator)转换为data.Dataset对象,以便在TensorFlow中使用。通过from_generator方法,创建一个可以高效加载数据的Dataset对象,并使用prefetch优化内存和计算性能。
2. 构建模型(model.py)
from tensorflow.keras.models import Model
from tensorflow.keras.layers import (
Input, Conv2D, BatchNormalization, Activation, MaxPooling2D,
Dropout, GlobalAveragePooling2D, Dense, Add, Concatenate,
DepthwiseConv2D, SeparableConv2D, LayerNormalization,
MultiHeadAttention
)
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
class DiseaseClassifier:
def __init__(self, config):
self.config = config
self.model = None
def _create_residual_block(self, x, filters, kernel_size=3):
"""创建残差块"""
shortcut = x
# 第一个卷积层
x = Conv2D(filters, kernel_size, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 第二个卷积层
x = Conv2D(filters, kernel_size, padding='same')(x)
x = BatchNormalization()(x)
# 如果输入和输出维度不同,需要调整shortcut
if shortcut.shape[-1] != filters:
shortcut = Conv2D(filters, 1, padding='same')(shortcut)
shortcut = BatchNormalization()(shortcut)
# 添加残差连接
x = Add()([x, shortcut])
x = Activation('relu')(x)
return x
def _create_attention_block(self, x, filters):
"""创建注意力块"""
# 空间注意力
mha = MultiHeadAttention(
num_heads=4,
key_dim=filters // 4
)(x, x)
x = LayerNormalization()(Add()([x, mha]))
return x
def _create_inception_block(self, x, filters):
"""创建Inception模块"""
# 1x1 卷积
conv1 = Conv2D(filters//4, 1, padding='same', activation='relu')(x)
# 1x1 -> 3x3 卷积
conv3 = Conv2D(filters//4, 1, padding='same', activation='relu')(x)
conv3 = Conv2D(filters//4, 3, padding='same', activation='relu')(conv3)
# 1x1 -> 5x5 卷积
conv5 = Conv2D(filters//4, 1, padding='same', activation='relu')(x)
conv5 = Conv2D(filters//4, 5, padding='same', activation='relu')(conv5)
# 3x3池化 -> 1x1卷积
pool = MaxPooling2D(3, strides=1, padding='same')(x)
pool = Conv2D(filters//4, 1, padding='same', activation='relu')(pool)
# 合并所有分支
return Concatenate()([conv1, conv3, conv5, pool])
def build_model(self, n_classes):
"""构建增强版CNN模型"""
inputs = Input(shape=(*self.config.IMG_SIZE, 3))
# 初始卷积块
x = Conv2D(32, 3, padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D()(x)
# 残差块 1
x = self._create_residual_block(x, 64)
x = MaxPooling2D()(x)
x = Dropout(0.25)(x)
# Inception块
x = self._create_inception_block(x, 128)
x = MaxPooling2D()(x)
x = Dropout(0.25)(x)
# 残差块 2
x = self._create_residual_block(x, 256)
x = MaxPooling2D()(x)
x = Dropout(0.25)(x)
# 注意力块
x = self._create_attention_block(x, 256)
# 全局平均池化
x = GlobalAveragePooling2D()(x)
# 全连接层
x = Dense(512, activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(0.5)(x)
# 输出层
outputs = Dense(n_classes, activation='softmax')(x)
# 创建模型
model = Model(inputs, outputs)
# 编译模型
optimizer = Adam(learning_rate=self.config.INITIAL_LEARNING_RATE)
model.compile(
optimizer=optimizer,
loss='categorical_crossentropy',
metrics=['accuracy']
)
self.model = model
return model
def load_model(self, model_path):
"""加载已训练的模型"""
self.model = tf.keras.models.load_model(model_path)
return self.model
def get_intermediate_model(self, layer_names):
"""获取一个新的模型,返回中间层的输出"""
# 获取中间层的输出
layer_outputs = [self.model.get_layer(name).output for name in layer_names]
intermediate_model = Model(inputs=self.model.input, outputs=layer_outputs)
return intermediate_model
这段代码定义了一个名为DiseaseClassifier的类,该类用于构建一个多层次增强型卷积神经网络(CNN)模型,主要应用于疾病分类任务。代码包含了多个子模块,旨在提升模型性能并通过不同的深度学习技术进行增强。以下是代码的主要功能概述:
- 初始化与模型设置:
- init(self, config):初始化时接受一个配置对象config,其中包含了图像尺寸、学习率等超参数配置。
- model:模型对象的初始化为空,后续将通过build_model方法创建。
- 模块化网络结构:
- 残差块 (_create_residual_block):创建了一个残差块,使用了两个卷积层,确保输入与输出的维度一致(通过调整shortcut)。这有助于减轻深度网络的梯度消失问题,提高训练效果。
- 注意力块 (_create_attention_block):使用了多头自注意力(Multi-Head Attention)模块,为模型增加了空间注意力机制。此模块旨在让模型关注输入特征中的重要部分,提高特征提取的能力。
- Inception块 (_create_inception_block):Inception模块通过多个不同大小的卷积核(1x1、3x3、5x5)提取多尺度特征,同时结合池化操作,增强了模型的多样性和对不同特征的敏感度。
- 构建增强版CNN模型:
- build_model(self, n_classes):这是模型的主构建函数。
- 输入:接受形状为(*self.config.IMG_SIZE, 3)的图像输入。
- 初始卷积层:使用Conv2D和MaxPooling2D对图像进行特征提取。
- 残差块:通过调用_create_residual_block添加残差模块以改善网络的学习能力。
- Inception块:通过调用_create_inception_block提取多尺度特征。
- 注意力块:通过_create_attention_block引入自注意力机制。
- 全局平均池化层:将特征图压缩为单一的向量表示。
- 全连接层:使用Dense和Dropout提高模型的非线性表达能力。
- 输出层:使用softmax激活函数进行多分类预测。
- 编译模型:使用Adam优化器,结合categorical_crossentropy损失函数,编译模型,准备训练。
- build_model(self, n_classes):这是模型的主构建函数。
- 加载和获取模型:
- load_model(self, model_path):用于加载已训练的模型,指定路径model_path。
- get_intermediate_model(self, layer_names):根据指定的中间层名称,返回一个新的模型,该模型输出中间层的特征,以便进行可视化或特征分析。
3. 回调(callbacks.py)
import tensorflow as tf
from tensorflow.keras.callbacks import (
ModelCheckpoint, EarlyStopping, TensorBoard,
ReduceLROnPlateau, CSVLogger, LambdaCallback
)
import os
import datetime
import json
import numpy as np
from tensorflow.keras import backend as K
class TrainingProgressCallback(tf.keras.callbacks.Callback):
"""自定义训练进度回调"""
def __init__(self, log_dir):
super().__init__()
self.log_dir = log_dir
def on_epoch_end(self, epoch, logs=None):
"""记录每个epoch的训练进度"""
logs = logs or {}
progress_file = os.path.join(self.log_dir, 'training_progress.json')
# 读取现有进度
if os.path.exists(progress_file):
with open(progress_file, 'r') as f:
progress = json.load(f)
else:
progress = []
# 获取当前学习率
if hasattr(self.model.optimizer, 'learning_rate'):
lr = float(K.eval(self.model.optimizer.learning_rate))
else:
lr = float(K.eval(self.model.optimizer.lr))
# 添加新的epoch数据
progress.append({
'epoch': epoch + 1,
'train_accuracy': float(logs.get('accuracy', 0)),
'train_loss': float(logs.get('loss', 0)),
'val_accuracy': float(logs.get('val_accuracy', 0)),
'val_loss': float(logs.get('val_loss', 0)),
'learning_rate': lr
})
# 保存进度
with open(progress_file, 'w') as f:
json.dump(progress, f, indent=4)
class PerformanceMonitorCallback(tf.keras.callbacks.Callback):
"""性能监控回调"""
def __init__(self, log_dir):
super().__init__()
self.log_dir = log_dir
self.batch_times = []
self.epoch_times = []
self.start_time = None
def on_train_begin(self, logs=None):
self.start_time = datetime.datetime.now()
def on_epoch_begin(self, epoch, logs=None):
self.epoch_start_time = datetime.datetime.now()
def on_epoch_end(self, epoch, logs=None):
epoch_time = (datetime.datetime.now() - self.epoch_start_time).total_seconds()
self.epoch_times.append(epoch_time)
# 记录性能指标
metrics = {
'epoch': epoch + 1,
'epoch_time': epoch_time,
'average_epoch_time': np.mean(self.epoch_times),
'total_time': (datetime.datetime.now() - self.start_time).total_seconds(),
}
# 保存性能指标
performance_file = os.path.join(self.log_dir, 'performance_metrics.json')
with open(performance_file, 'w') as f:
json.dump(metrics, f, indent=4)
class TrainingCallbacks:
def __init__(self, config):
self.config = config
def get_callbacks(self):
"""设置训练回调函数"""
# 创建日志目录
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
log_dir = os.path.join(self.config.LOG_DIR, current_time)
os.makedirs(log_dir, exist_ok=True)
callbacks = []
# TensorBoard回调
tensorboard = TensorBoard(
log_dir=log_dir,
histogram_freq=1,
write_graph=True,
write_images=True,
update_freq='epoch',
profile_batch=2
)
callbacks.append(tensorboard)
# CSV日志记录
csv_logger = CSVLogger(
os.path.join(log_dir, 'training_log.csv'),
separator=',',
append=False
)
callbacks.append(csv_logger)
# 模型检查点
checkpoint = ModelCheckpoint(
filepath=os.path.join(self.config.CHECKPOINT_DIR, 'model-{epoch:02d}-{val_accuracy:.4f}.keras'),
monitor='val_accuracy',
save_best_only=True,
mode='max',
verbose=1
)
callbacks.append(checkpoint)
# 早停
early_stopping = EarlyStopping(
monitor='val_loss',
patience=10,
restore_best_weights=True,
verbose=1
)
callbacks.append(early_stopping)
# 学习率调整
reduce_lr = ReduceLROnPlateau(
monitor='val_loss',
factor=0.2,
patience=5,
min_lr=self.config.MIN_LEARNING_RATE,
verbose=1
)
callbacks.append(reduce_lr)
# 训练进度回调
training_progress = TrainingProgressCallback(log_dir)
callbacks.append(training_progress)
# 性能监控回调
performance_monitor = PerformanceMonitorCallback(log_dir)
callbacks.append(performance_monitor)
return callbacks
这段代码定义了一个用于训练过程中监控和回调的类TrainingCallbacks,并实现了几个自定义的回调函数,用于跟踪训练过程中的各种指标,如进度、性能、日志等。以下是代码的主要功能概述:
- 自定义回调:
- TrainingProgressCallback:该回调在每个训练周期(epoch)结束时保存训练进度到training_progress.json文件。它记录了每个epoch的训练和验证准确率、损失值以及当前的学习率。学习率是从优化器中动态获取的。保存的内容:epoch, train_accuracy, train_loss, val_accuracy, val_loss, learning_rate。
- PerformanceMonitorCallback:该回调用于监控训练过程的性能,包括每个epoch的耗时、平均epoch时间以及训练的总时间。所有这些性能数据会保存到performance_metrics.json文件中。保存的内容:epoch, epoch_time, average_epoch_time, total_time。
- 训练回调集合 (TrainingCallbacks):
- init(self, config):初始化时接受一个配置对象config,该对象包含一些训练参数,如日志目录、检查点目录等。
- get_callbacks(self):
- 该方法负责创建和配置多个回调函数,用于训练过程中的不同目的。它包括以下几个回调:
- TensorBoard:用于可视化训练过程中的损失、准确率等指标。训练过程中生成的日志会存储在log_dir目录下,日志可以用于TensorBoard的图形界面展示。
- CSVLogger:记录训练过程中的每个epoch的日志信息(如准确率、损失值)到training_log.csv文件。
- ModelCheckpoint:保存验证准确率最好的模型。文件名中包含当前epoch号和验证准确率。
- EarlyStopping:用于防止过拟合。当验证损失在连续若干个epoch内没有改善时停止训练,并恢复到最好的模型权重。
- ReduceLROnPlateau:当验证损失在若干个epoch内没有改善时,降低学习率。学习率不会下降低于MIN_LEARNING_RATE。
- TrainingProgressCallback:用于记录每个epoch结束后的训练进度(包括训练和验证的准确率、损失以及当前学习率)。
- PerformanceMonitorCallback:记录每个epoch的训练时间和整体训练时间。
- 训练过程中的文件存储:
- 日志文件:所有回调都会在训练过程中生成或更新不同的日志文件,记录训练的详细信息。这些日志文件包括:
- training_log.csv:包含每个epoch的训练日志。
- training_progress.json:包含训练和验证的进度数据(如准确率、损失等)。
- performance_metrics.json:包含训练的性能监控数据(如每个epoch的训练时间、总训练时间等)。
- model-{epoch:02d}-{val_accuracy:.4f}.keras:保存最佳模型(基于验证准确率)。
- 日志文件:所有回调都会在训练过程中生成或更新不同的日志文件,记录训练的详细信息。这些日志文件包括:
4. 训练(train.py)
import tensorflow as tf
import os
import datetime
import gc
import numpy as np
from tensorflow.keras import backend as K
from config.config import Config
from data.data_generator import DataGenerator
from models.model import DiseaseClassifier
from models.callbacks import TrainingCallbacks
from utils.utils import Visualizer, ModelAnalyzer, Logger
def setup_visualization():
"""设置可视化环境"""
# 创建可视化目录
vis_dir = os.path.join(Config.OUTPUT_DIR, 'visualizations')
os.makedirs(vis_dir, exist_ok=True)
# 配置TensorBoard
log_dir = os.path.join(Config.LOG_DIR, datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
return log_dir, vis_dir
def get_predictions(model, data_generator):
"""
获取模型预测结果和真实标签
"""
# 重置数据生成器
data_generator.reset()
# 获取预测结果
predictions = model.predict(data_generator, verbose=1)
predicted_classes = np.argmax(predictions, axis=1)
# 获取真实标签和类别名称
true_classes = data_generator.classes
class_names = list(data_generator.class_indices.keys())
return true_classes, predicted_classes, class_names
def train():
# 创建日志记录器
logger = Logger(Config.LOG_DIR)
# 设置可视化
log_dir, vis_dir = setup_visualization()
logger.log(f"[信息] TensorBoard日志目录: {log_dir}")
logger.log(f"[信息] 可视化输出目录: {vis_dir}")
# 获取分布式策略
strategy = tf.distribute.get_strategy()
logger.log(f"[信息] 使用 {strategy.num_replicas_in_sync} 个计算设备进行训练")
try:
with strategy.scope():
# 准备数据生成器
logger.log("[信息] 准备数据生成器...")
data_generator = DataGenerator(Config)
train_generator, valid_generator = data_generator.create_generators()
# 构建模型
logger.log("[信息] 构建模型...")
classifier = DiseaseClassifier(Config)
model = classifier.build_model(train_generator.num_classes)
# 设置回调函数,包括可视化回调
callbacks = TrainingCallbacks(Config).get_callbacks()
# 打印模型信息
ModelAnalyzer.print_model_summary(model)
# 将模型结构保存为图像
tf.keras.utils.plot_model(
model,
to_file=os.path.join(vis_dir, 'model_architecture.png'),
show_shapes=True,
show_layer_names=True,
rankdir='TB'
)
# 训练模型
logger.log("[信息] 开始训练模型...")
history = model.fit(
train_generator,
validation_data=valid_generator,
epochs=Config.EPOCHS,
callbacks=callbacks,
verbose=1
)
# 保存最终模型
model_dir = os.path.join(Config.MODEL_DIR)
os.makedirs(model_dir, exist_ok=True)
final_model_path = os.path.join(Config.MODEL_DIR, 'final_model.keras')
model.save(final_model_path)
logger.log(f"[信息] 最终模型已保存至: {final_model_path}")
# 保存训练历史
history_path = os.path.join(vis_dir, 'training_history.png')
Visualizer.plot_training_history(history, history_path)
# 打印训练总结
logger.log("\n训练总结:")
logger.log(f"最佳验证准确率: {max(history.history['val_accuracy']):.4f}")
logger.log(f"最佳训练准确率: {max(history.history['accuracy']):.4f}")
logger.log(f"最终验证损失: {min(history.history['val_loss']):.4f}")
# 提示TensorBoard使用方法
logger.log("\n要查看详细的训练可视化,请在命令行运行:")
logger.log(f"tensorboard --logdir={log_dir}")
except Exception as e:
logger.log(f"[错误] 训练过程中出现错误: {str(e)}")
raise
finally:
# 清理资源
K.clear_session()
gc.collect()
if __name__ == "__main__":
train()
这段代码的作用是为深度学习模型的训练提供一个完整的训练管道,包括:数据准备、模型构建、分布式训练支持、模型训练与回调、训练过程中日志记录、可视化、资源清理等。 通过可视化和日志文件,用户可以跟踪训练进度、查看训练历史,并分析训练过程中出现的问题。其中:多GPU训练支持:适合需要大规模计算资源的训练任务。监控与可视化:通过TensorBoard和训练历史图表,用户可以实时查看模型训练过程,帮助诊断潜在问题。自动化训练过程:自定义回调函数支持训练过程的自动化管理和性能优化。
5. 评估代码(evaluate.py)
import tensorflow as tf
import os
import numpy as np
from sklearn.metrics import accuracy_score, precision_recall_fscore_support, confusion_matrix, f1_score
import matplotlib.pyplot as plt
import seaborn as sns
from config.config import Config
from data.data_generator import DataGenerator
from utils.utils import Visualizer, Logger
from models.model import DiseaseClassifier
from models.callbacks import TrainingCallbacks
def setup_visualization():
"""设置可视化环境"""
# 创建可视化目录
vis_dir = os.path.join(Config.OUTPUT_DIR, 'visualizations')
os.makedirs(vis_dir, exist_ok=True)
return vis_dir
def get_predictions(model, data_generator):
"""
获取模型预测结果和真实标签
"""
# 重置数据生成器
data_generator.reset()
# 获取预测结果
predictions = model.predict(data_generator, verbose=1)
predicted_classes = np.argmax(predictions, axis=1)
# 获取真实标签和类别名称
true_classes = data_generator.classes
print(true_classes)
class_names = list(data_generator.class_indices.keys())
return true_classes, predicted_classes, class_names
def evaluate():
# 创建日志记录器
logger = Logger(Config.LOG_DIR)
# 设置可视化
vis_dir = setup_visualization()
logger.log(f"[信息] 可视化输出目录: {vis_dir}")
try:
# 加载模型
logger.log("[信息] 加载训练好的模型...")
model_path = os.path.join(Config.MODEL_DIR, 'final_model.keras')
model = tf.keras.models.load_model(model_path)
# 获取数据生成器
logger.log("[信息] 准备数据生成器...")
data_generator = DataGenerator(Config)
_, valid_generator = data_generator.create_generators()
# 获取预测结果
y_true, y_pred, class_names = get_predictions(model, valid_generator)
# 计算分类指标
logger.log("[信息] 计算分类指标...")
# 准确率
accuracy = accuracy_score(y_true, y_pred)
logger.log(f"Overall Accuracy: {accuracy:.4f}")
# 精确度、召回率、F1 score
precision, recall, f1, _ = precision_recall_fscore_support(y_true, y_pred, average=None)
# 输出每个类别的精确度、召回率、F1 score
for i, class_name in enumerate(class_names):
logger.log(f"Class {class_name}:")
logger.log(f" 精确度: {precision[i]:.4f}")
logger.log(f" 召回率: {recall[i]:.4f}")
logger.log(f" F1 Score: {f1[i]:.4f}")
# 加权平均精确度、召回率、F1 score
weighted_precision = np.average(precision, weights=np.bincount(y_true))
weighted_recall = np.average(recall, weights=np.bincount(y_true))
weighted_f1 = np.average(f1, weights=np.bincount(y_true))
logger.log(f"\n加权平均精确度: {weighted_precision:.4f}")
logger.log(f"加权召回率: {weighted_recall:.4f}")
logger.log(f"加权 F1 Score: {weighted_f1:.4f}")
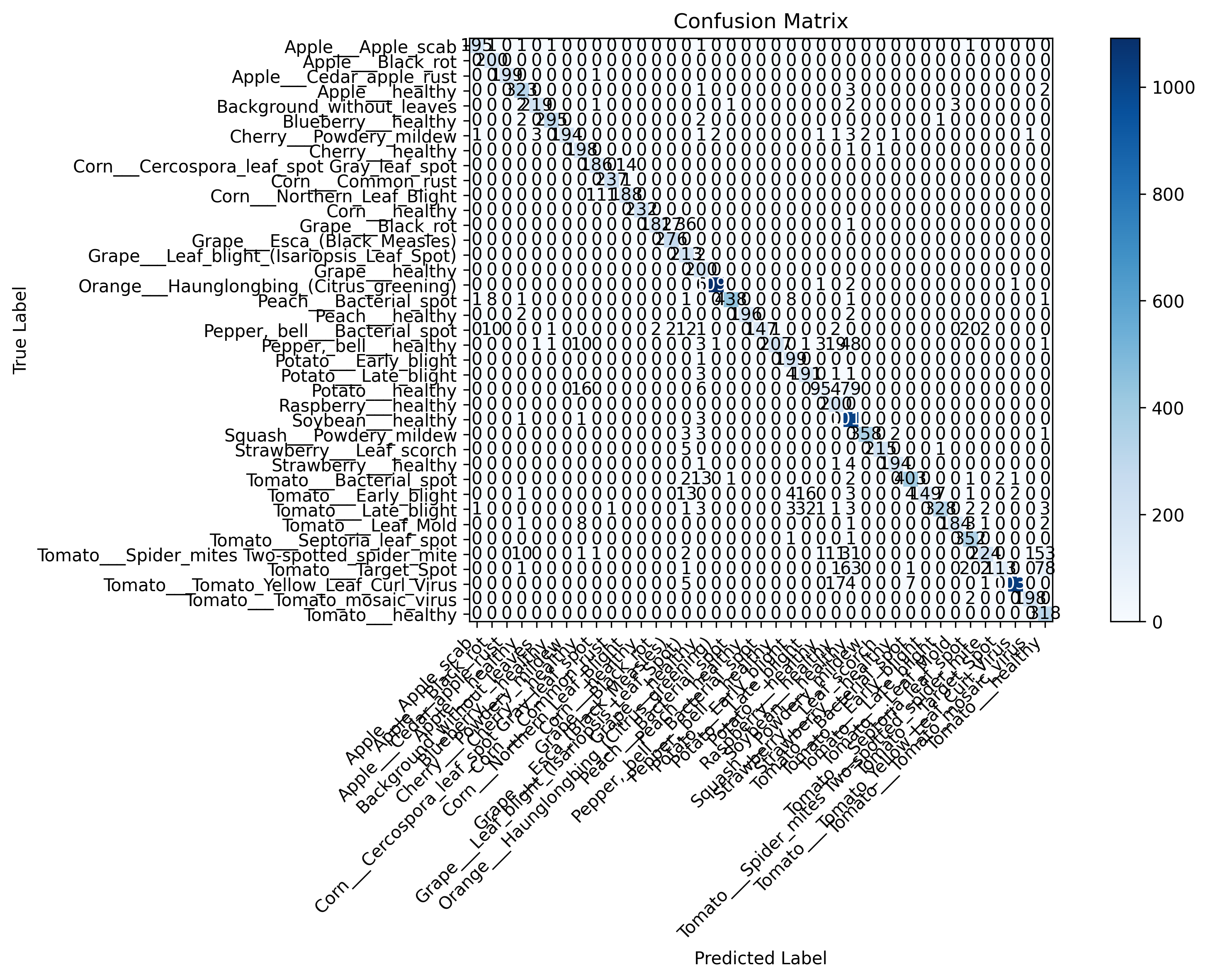
# 生成混淆矩阵
logger.log("[信息] 生成混淆矩阵...")
y_true, y_pred, class_names = get_predictions(model, valid_generator)
confusion_matrix_path = os.path.join(vis_dir, 'confusion_matrix.png')
Visualizer.plot_confusion_matrix(
y_true,
y_pred,
class_names,
confusion_matrix_path
)
# 总体加权 F1 score
overall_f1 = f1_score(y_true, y_pred, average='weighted')
logger.log(f"总体加权 F1 Score: {overall_f1:.4f}")
except Exception as e:
logger.log(f"[错误] 评估过程中出现错误: {str(e)}")
raise
if __name__ == "__main__":
evaluate()
这段代码完成了模型评估的核心任务,包括:加载训练后的模型并评估其在验证集上的性能。计算并输出常见分类指标(如准确率、精确度、召回率、F1 Score)。生成并保存混淆矩阵。记录日志信息,帮助分析模型性能。
6. 模型的特征映射可视化(get_feature_maps.py)
import os
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import load_model
from config.config import Config
from data.data_generator import DataGenerator
from models.model import DiseaseClassifier
from utils.utils import Logger
def visualize_feature_maps(model, img_path, layer_names=None):
"""
可视化模型每一层的特征映射图。
:param model: 训练好的模型
:param img_path: 图像路径
:param layer_names: 要可视化的层名称列表(如果为 None,将显示所有卷积层)
"""
# 加载并预处理图像
img = image.load_img(img_path, target_size=Config.IMG_SIZE)
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0) # 添加批次维度
img_array = img_array / 255.0 # 如果模型是用归一化数据训练的
# 如果没有指定层名称,则默认选择所有卷积层
if layer_names is None:
layer_names = [layer.name for layer in model.layers if 'conv' in layer.name]
# 创建一个新的模型,输出每层的特征图
layer_outputs = [model.get_layer(name).output for name in layer_names]
feature_map_model = tf.keras.models.Model(inputs=model.input, outputs=layer_outputs)
# 获取特征映射
feature_maps = feature_map_model.predict(img_array)
# 可视化每层的特征图
for layer_name, feature_map in zip(layer_names, feature_maps):
folder = f"output/feature_maps/feature_map_{layer_name}.png"
num_feature_maps = feature_map.shape[-1] # 获取通道数(特征图数量)
# 创建一个子图,用来显示所有的特征图
size = int(np.ceil(np.sqrt(num_feature_maps))) # 每行显示的特征图数量
fig, axes = plt.subplots(size, size, figsize=(10, 10))
for i in range(num_feature_maps):
ax = axes[i // size, i % size]
ax.imshow(feature_map[0, :, :, i], cmap='viridis')
ax.axis('off')
plt.suptitle(f"Feature Maps of Layer: {layer_name}", size=16)
plt.tight_layout()
plt.subplots_adjust(top=0.95)
plt.imsave(folder, feature_map)
def get_feature_maps():
# 创建日志记录器
logger = Logger(Config.LOG_DIR)
try:
# 加载模型
logger.log("[信息] 加载训练好的模型...")
# 从 checkpoint 加载模型
model_path = os.path.join(Config.MODEL_DIR, 'final_model.keras')
model = load_model(model_path)
# 加载数据生成器
logger.log("[信息] 加载数据生成器...")
data_generator = DataGenerator(Config)
_, valid_generator = data_generator.create_generators()
# 获取一张图像进行可视化
img_path = valid_generator.filepaths[0] # 取验证集的第一张图像
# 可视化特征图
logger.log("[信息] 可视化特征映射图...")
visualize_feature_maps(model, img_path)
except Exception as e:
logger.log(f"[错误] 获取特征图过程中出现错误: {str(e)}")
raise
if __name__ == "__main__":
get_feature_maps()
这段代码实现了模型的特征映射可视化功能,具体包括加载训练好的模型,选择一张图像,提取和可视化卷积层的特征图。特征图可以帮助我们理解模型在处理图像时是如何学习不同的特征(如边缘、纹理、形状等)。以下是代码的详细解析:
- 输入:
- model:训练好的深度学习模型。
- img_path:图像路径,用于从中提取特征图。
- layer_names:需要可视化的层名称列表。如果没有指定,默认可视化所有卷积层。
- 步骤:
- 图像加载与预处理:使用load_img和image.img_to_array加载并转换图像,使其符合模型的输入要求(大小为Config.IMG_SIZE,并归一化处理)。
- 选择卷积层:如果没有指定层名称,代码会自动选择所有包含”conv”的层名作为默认选择,这些通常是卷积层。
- 获取特征映射:使用Model类创建一个新的模型,该模型的输出是指定层的特征图。使用predict获取这些层的特征映射。
- 可视化特征图:对每一层的特征图进行可视化,并保存到指定目录(output/feature_maps/)。每个特征图通过matplotlib显示在多个子图中,大小为size,并使用viridis颜色图。通过imsave将每个特征图保存为图像文件。
7. Gradio可视化(gradio_interface.py)
import gradio as gr
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing import image
import matplotlib.pyplot as plt
from tensorflow.keras.models import load_model
from PIL import Image, ImageDraw, ImageFont
import io
import os
class Config:
MODEL_DIR = 'models'
IMG_SIZE = (128, 128)
CLASS_NAMES = [
'Apple___Apple_scab', 'Apple___Black_rot', 'Apple___Cedar_apple_rust',
'Apple___healthy', 'Background_without_leaves', 'Blueberry___healthy',
'Cherry___Powdery_mildew', 'Cherry___healthy',
'Corn___Cercospora_leaf_spot Gray_leaf_spot', 'Corn___Common_rust',
'Corn___Northern_Leaf_Blight', 'Corn___healthy', 'Grape___Black_rot',
'Grape___Esca_(Black_Measles)', 'Grape___Leaf_blight_(Isariopsis_Leaf_Spot)',
'Grape___healthy', 'Orange___Haunglongbing_(Citrus_greening)',
'Peach___Bacterial_spot', 'Peach___healthy', 'Pepper,_bell___Bacterial_spot',
'Pepper,_bell___healthy', 'Potato___Early_blight', 'Potato___Late_blight',
'Potato___healthy', 'Raspberry___healthy', 'Soybean___healthy',
'Squash___Powdery_mildew', 'Strawberry___Leaf_scorch', 'Strawberry___healthy',
'Tomato___Bacterial_spot', 'Tomato___Early_blight', 'Tomato___Late_blight',
'Tomato___Leaf_Mold', 'Tomato___Septoria_leaf_spot',
'Tomato___Spider_mites Two-spotted_spider_mite', 'Tomato___Target_Spot',
'Tomato___Tomato_Yellow_Leaf_Curl_Virus', 'Tomato___Tomato_mosaic_virus',
'Tomato___healthy'
]
_model = None
def get_model():
global _model
if _model is None:
_model = load_model('output/models/final_model.keras')
return _model
def preprocess_image(img):
img_resized = img.resize(Config.IMG_SIZE)
img_array = image.img_to_array(img_resized)
img_array = np.expand_dims(img_array, axis=0)
return img_array / 255.0
def fig_to_image(fig):
buf = io.BytesIO()
fig.savefig(buf, format='png', bbox_inches='tight')
buf.seek(0)
return Image.open(buf)
def visualize_feature_maps(model, img_array):
conv_layers = [layer.name for layer in model.layers if 'conv2d' in layer.name][:4]
outputs = [model.get_layer(name).output for name in conv_layers]
vis_model = tf.keras.models.Model(model.input, outputs)
feature_maps = vis_model.predict(img_array)
images = []
for idx, fmap in enumerate(feature_maps):
fig = plt.figure(figsize=(8, 8))
plt.title(f"Conv Layer {idx+1}")
n_features = min(16, fmap.shape[-1])
grid_size = int(np.ceil(np.sqrt(n_features)))
for i in range(n_features):
plt.subplot(grid_size, grid_size, i + 1)
plt.imshow(fmap[0, :, :, i], cmap='viridis')
plt.axis('off')
img = fig_to_image(fig)
images.append(img)
plt.close(fig)
return images
def predict_and_visualize(img):
if img is None:
return None, "请上传图片", None
try:
model = get_model()
img_array = preprocess_image(img)
pred = model.predict(img_array)
pred_class = np.argmax(pred[0])
confidence = pred[0][pred_class]
img_with_text = img.copy()
draw = ImageDraw.Draw(img_with_text)
font = ImageFont.load_default()
class_name = Config.CLASS_NAMES[pred_class]
prediction_text = f"{class_name}\n{confidence:.2%}"
draw.text((10, 10), prediction_text, fill='red', font=font)
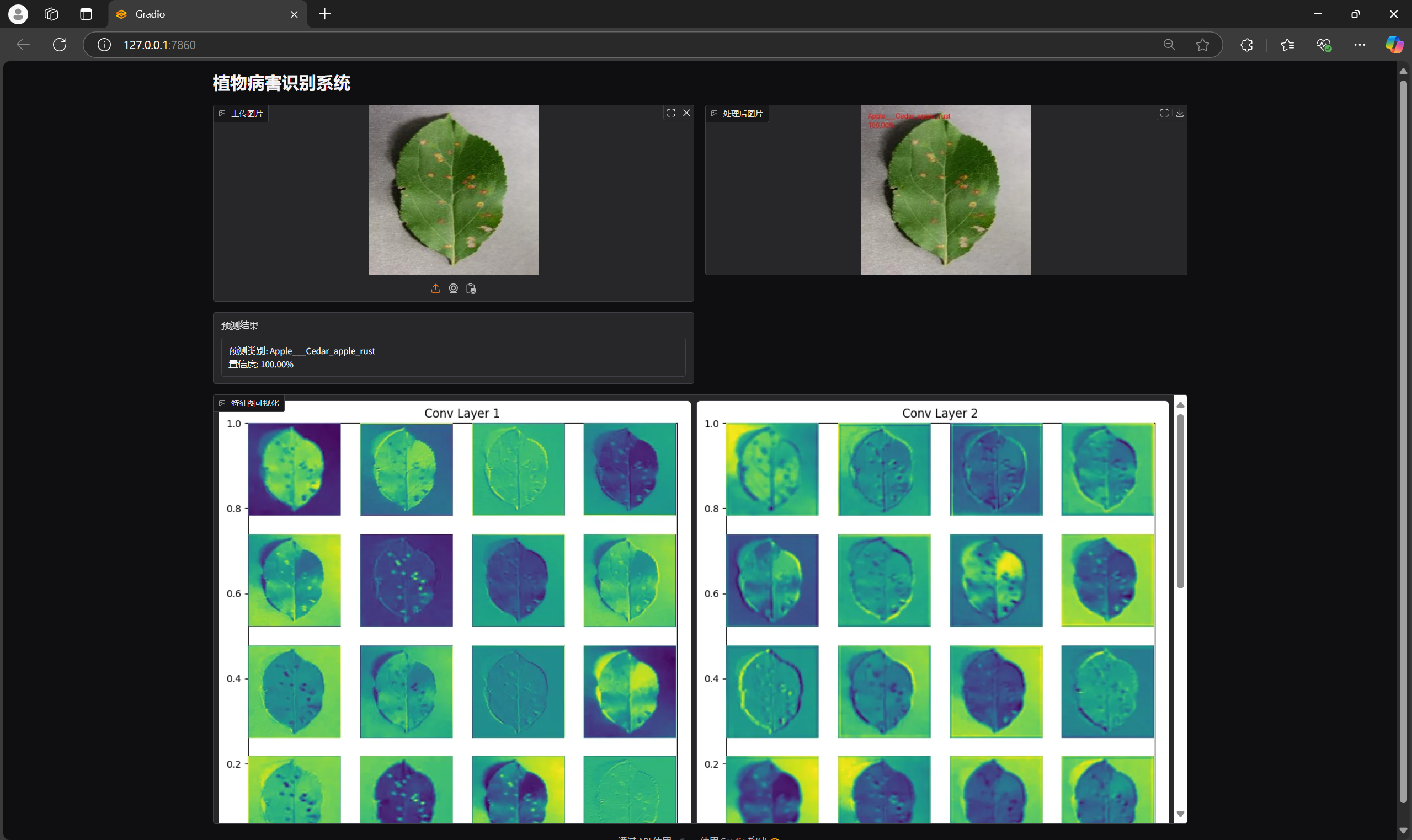
feature_maps = visualize_feature_maps(model, img_array)
result_text = f"预测类别: {class_name}\n置信度: {confidence:.2%}"
return img_with_text, result_text, feature_maps
except Exception as e:
return img, f"处理出错: {str(e)}", None
def create_interface():
with gr.Blocks() as interface:
gr.Markdown("# 植物病害识别系统")
with gr.Row():
with gr.Column():
input_image = gr.Image(type="pil", label="上传图片")
prediction_text = gr.Textbox(label="预测结果")
output_image = gr.Image(type="pil", label="处理后图片")
feature_maps = gr.Gallery(label="特征图可视化")
input_image.change(
fn=predict_and_visualize,
inputs=input_image,
outputs=[output_image, prediction_text, feature_maps]
)
return interface
if __name__ == "__main__":
interface = create_interface()
interface.launch()
这段代码构建了一个基于Gradio的交互式界面,用于植物病害的图像分类和特征图可视化。用户可以上传植物病害的图片,系统会预测图像的类别,并在图像上显示预测结果。除此之外,系统还会展示神经网络每个卷积层的特征图,以帮助理解模型的工作原理。
8. 其他文件(utils.py和config.py)
import os
import tensorflow as tf
class Config:
# 基础路径
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 数据相关配置
DATA_DIR = 'Plant_leave_diseases_dataset_with_augmentation'
IMG_SIZE = (128, 128)
BATCH_SIZE = 32
VALIDATION_SPLIT = 0.2
# 训练相关配置
EPOCHS = 50
INITIAL_LEARNING_RATE = 1e-3
MIN_LEARNING_RATE = 1e-6
# 输出目录配置
OUTPUT_DIR = os.path.join(BASE_DIR, 'output')
MODEL_DIR = os.path.join(OUTPUT_DIR, 'models')
LOG_DIR = os.path.join(OUTPUT_DIR, 'logs')
CHECKPOINT_DIR = os.path.join(OUTPUT_DIR, 'checkpoints')
import matplotlib.pyplot as plt
import numpy as np
import os
import cv2
from sklearn.metrics import confusion_matrix, classification_report
import tensorflow as tf
from tensorflow.keras import backend as K
import json
from datetime import datetime
class Visualizer:
"""可视化工具类:用于绘制训练过程和结果的各种图表"""
@staticmethod
def plot_training_history(history, save_path=None):
"""
绘制训练历史曲线
:param history: 训练历史对象
:param save_path: 图表保存路径
"""
# 使用内置的样式
plt.style.use('default')
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
fig.patch.set_facecolor('white')
# 绘制准确率曲线
ax1.plot(history.history['accuracy'], label='Training Accuracy',
color='#2ecc71', marker='o', markersize=4, linewidth=2)
ax1.plot(history.history['val_accuracy'], label='Validation Accuracy',
color='#e74c3c', marker='o', markersize=4, linewidth=2)
ax1.set_title('Model Accuracy', pad=15, fontsize=12)
ax1.set_xlabel('Epochs', fontsize=10)
ax1.set_ylabel('Accuracy', fontsize=10)
ax1.legend(loc='lower right', fontsize=10)
ax1.grid(True, linestyle='--', alpha=0.7)
ax1.set_facecolor('#f8f9fa')
# 绘制损失曲线
ax2.plot(history.history['loss'], label='Training Loss',
color='#3498db', marker='o', markersize=4, linewidth=2)
ax2.plot(history.history['val_loss'], label='Validation Loss',
color='#e67e22', marker='o', markersize=4, linewidth=2)
ax2.set_title('Model Loss', pad=15, fontsize=12)
ax2.set_xlabel('Epochs', fontsize=10)
ax2.set_ylabel('Loss', fontsize=10)
ax2.legend(loc='upper right', fontsize=10)
ax2.grid(True, linestyle='--', alpha=0.7)
ax2.set_facecolor('#f8f9fa')
# 调整布局
plt.tight_layout()
if save_path:
# 确保保存路径存在
os.makedirs(os.path.dirname(save_path), exist_ok=True)
plt.savefig(save_path, dpi=300, bbox_inches='tight', facecolor='white')
print(f"[信息] 训练历史图表已保存至: {save_path}")
plt.show()
plt.close()
@staticmethod
def plot_confusion_matrix(y_true, y_pred, classes, save_path=None):
"""
绘制混淆矩阵
:param y_true: 真实标签
:param y_pred: 预测标签
:param classes: 类别名称列表
:param save_path: 保存路径
"""
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(12, 8))
# 创建热力图
im = plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.colorbar(im)
# 设置标签
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, ha='right')
plt.yticks(tick_marks, classes)
# 添加数值
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
plt.text(j, i, format(cm[i, j], 'd'),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
plt.title('Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
print(f"[信息] 混淆矩阵已保存至: {save_path}")
plt.show()
plt.close()
class ModelAnalyzer:
"""模型分析工具类:用于分析和评估模型性能"""
@staticmethod
def print_model_summary(model):
"""
打印模型详细信息
:param model: Keras模型对象
"""
print("\n" + "="*50)
print("模型架构摘要:")
print("="*50)
model.summary()
# 使用tf.keras.backend的函数计算参数
total_params = model.count_params()
trainable_params = sum([tf.size(w).numpy() for w in model.trainable_weights])
non_trainable_params = sum([tf.size(w).numpy() for w in model.non_trainable_weights])
print("\n" + "="*50)
print("模型参数统计:")
print("="*50)
print(f"总参数量: {total_params:,}")
print(f"可训练参数: {trainable_params:,}")
print(f"非训练参数: {non_trainable_params:,}")
print(f"模型大小估计: {total_params * 4 / (1024*1024):.2f} MB\n")
class Logger:
"""日志工具类:用于记录训练过程和结果"""
def __init__(self, log_dir):
"""
初始化日志记录器
:param log_dir: 日志保存目录
"""
self.log_dir = log_dir
os.makedirs(log_dir, exist_ok=True)
self.log_file = os.path.join(log_dir,
f"training_log_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt")
def log(self, message):
"""
记录日志信息
:param message: 日志信息
"""
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log_message = f"[{timestamp}] {message}"
print(log_message)
with open(self.log_file, 'a', encoding='utf-8') as f:
f.write(log_message + '\n')
def log_metrics(self, metrics):
"""
记录训练指标
:param metrics: 指标字典
"""
self.log("\n训练指标:")
for key, value in metrics.items():
self.log(f"{key}: {value}")
结果展示
-
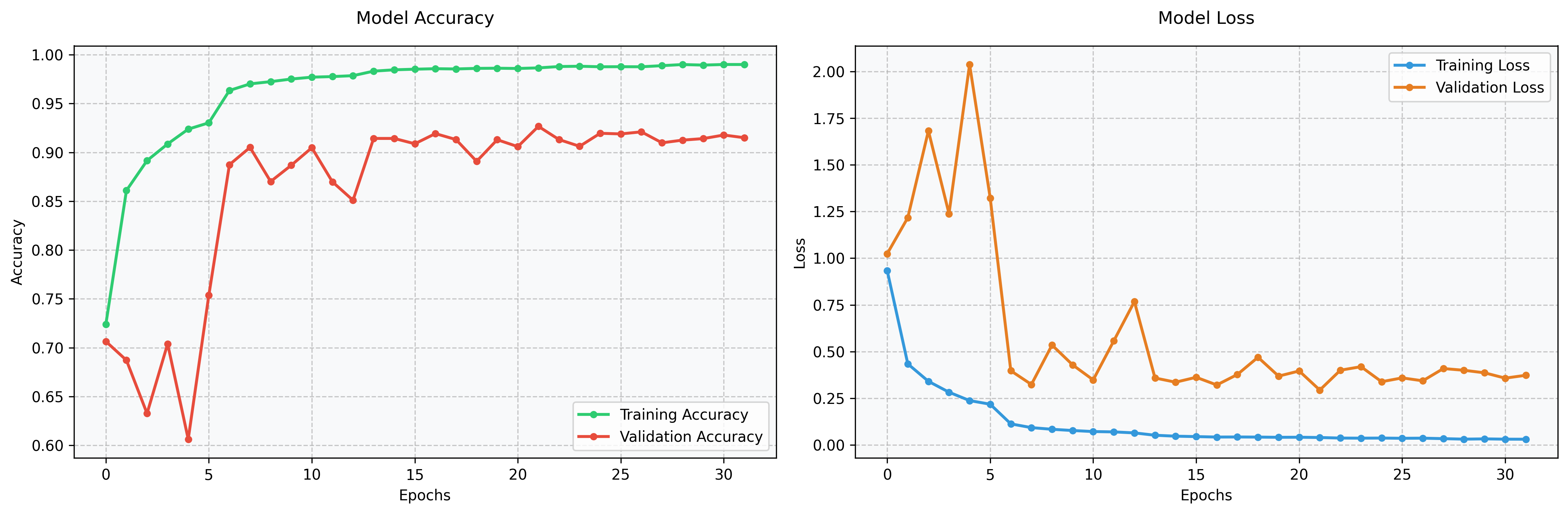
运行train.py
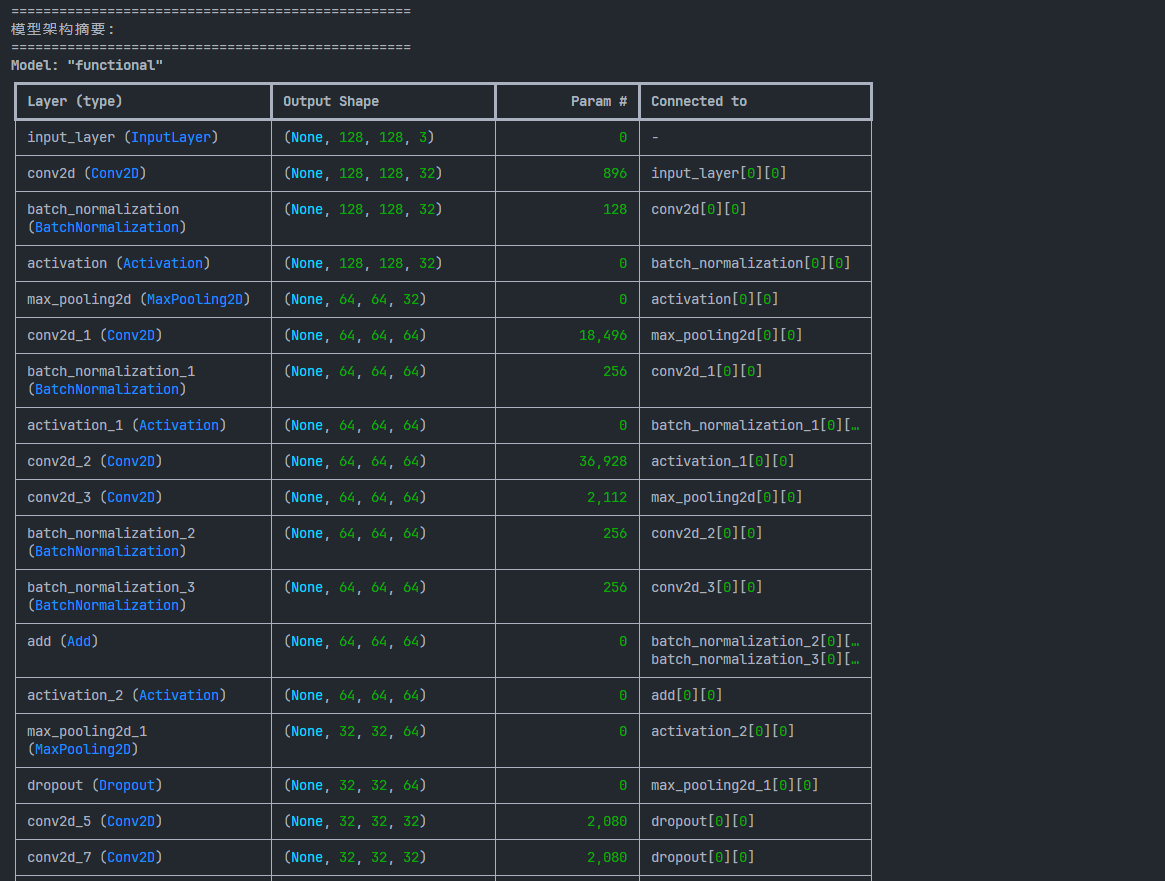
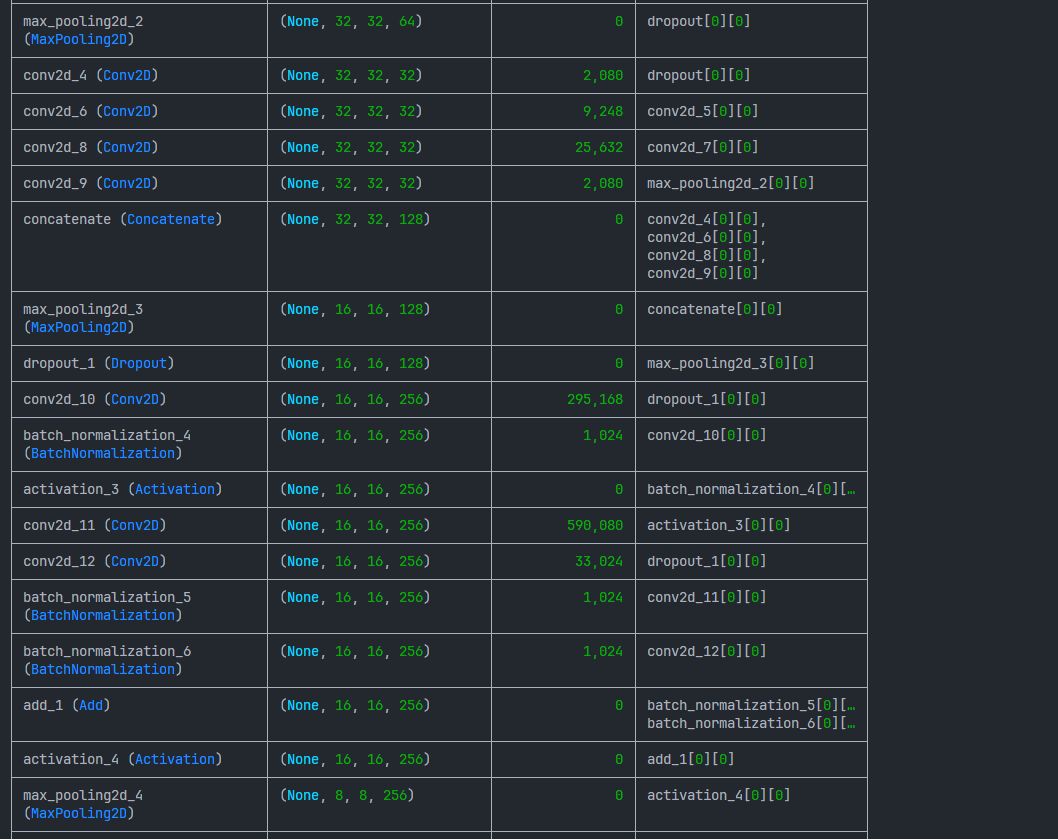
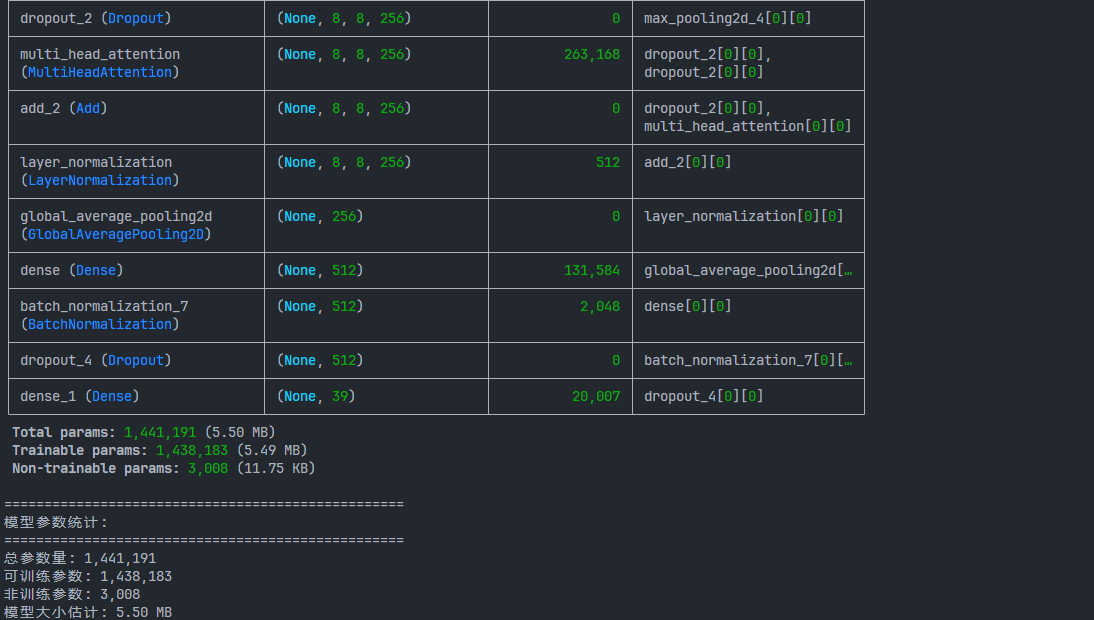
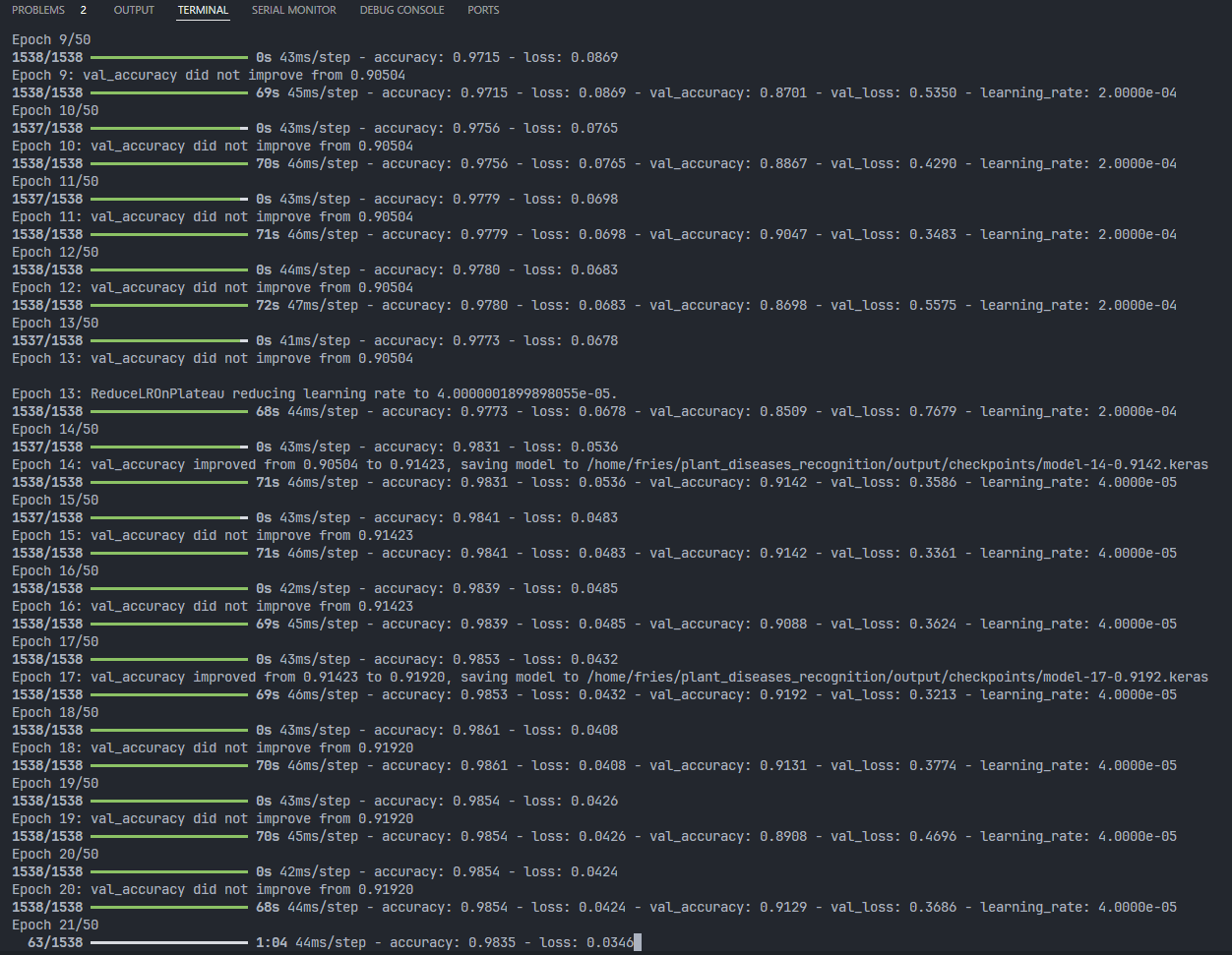
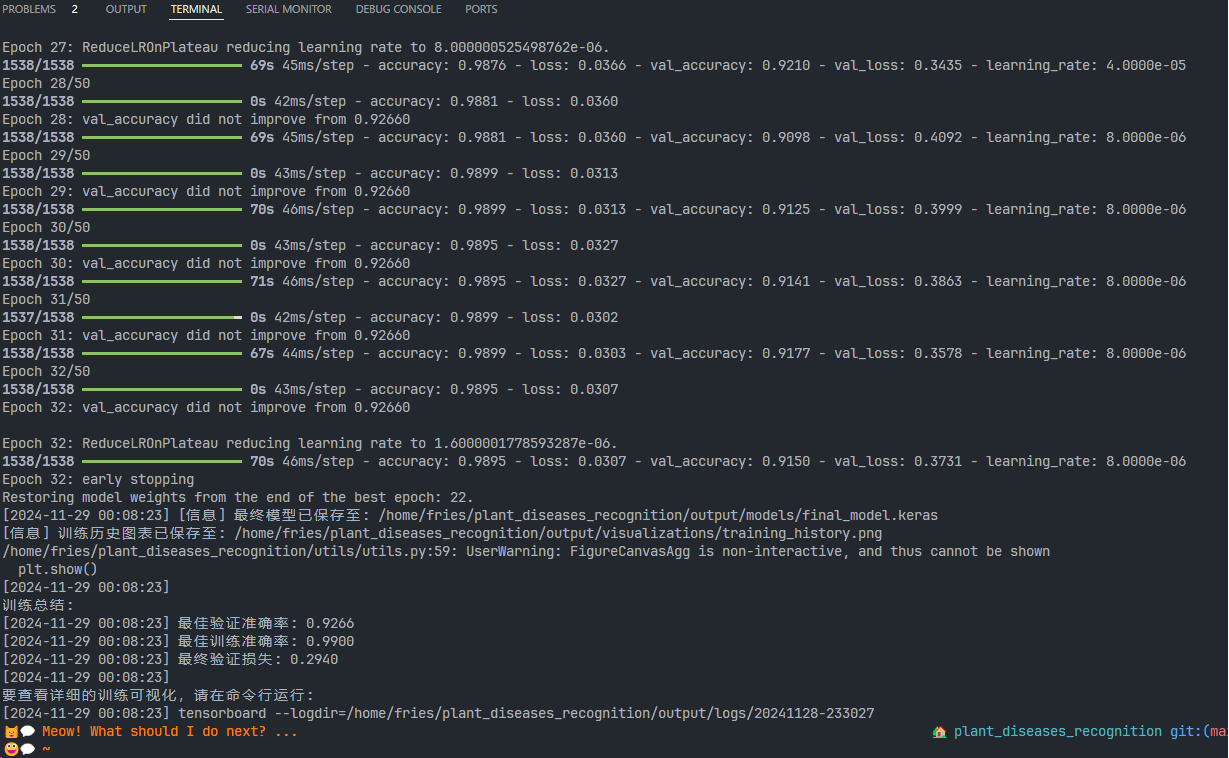
生成的模型结构图与训练趋势图
-
运行evaluate.py
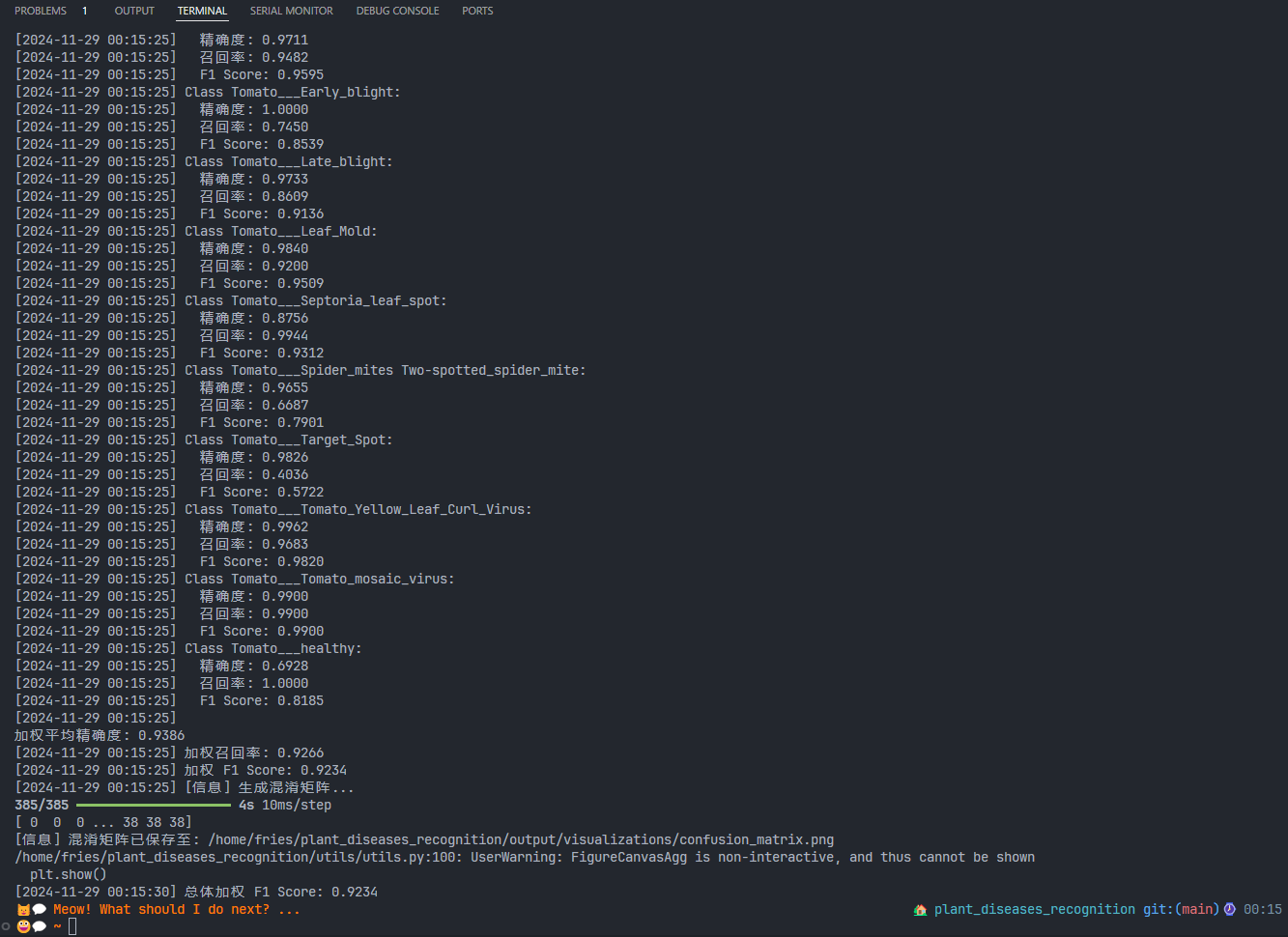
-
运行gradio_interface.py