说明:此文为笔者担任学校人工智能社团社长时,所主持开展的社团主题讲座《人工智能概述》的完整讲稿,在此分享给大家,供大家简要了解AI
一、人工智能热潮
大家应该都知道,最近诺贝尔奖的颁发再次引发了全球的广泛关注,其中物理学和化学的诺贝尔奖都与人工智能领域有着密切的联系。化学奖授予了英国科学家、AlphaFold开发者、DeepMind公司CEO戴米斯·哈萨比斯(Demis Hassabis)和其高级研究科学家约翰·江珀(John M. Jumper),以表彰他们通过机器学习成功预测蛋白质结构,解决了困扰科学界50年的难题。

与此同时,2024年诺贝尔物理学奖授予了美国科学家约翰·约瑟夫·霍普菲尔德(John J. Hopfield)和加拿大科学家杰弗里·辛顿(Geoffrey E. Hinton),表彰他们在人工神经网络和机器学习领域的基础性贡献。自20世纪80年代起,霍普菲尔德和辛顿就开展了与物理学和神经网络相关的开创性研究。霍普菲尔德最著名的研究成果是Hopfield神经网络,这是一种递归神经网络,通过能量最小化的方式存储和检索信息,广泛应用于联想记忆和组合优化问题。而辛顿则以推广反向传播算法著称,反向传播算法通过计算误差梯度来调整神经网络中的权重,极大地推动了深度神经网络的发展,使机器学习取得了长足进展。两位科学家的研究共同奠定了现代机器学习的基础。

这些成就不仅是对他们个人的巨大认可,也再次彰显了人工智能在当今科学领域中的深远影响力。AI已经不再是一个理论概念,它如今正在推动各个领域的变革,从生物化学到物理学,AI正展现出其前所未有的潜力。
如今,人工智能的应用无处不在,生活中我们每天都在与AI打交道,比如大家熟悉的ChatGPT,它可以帮助我们生成文本、回答问题,甚至进行复杂的对话。AI的热潮不仅限于对话系统,它已经广泛应用于自动驾驶、图像识别、医疗诊断等众多领域,AI似乎已经成为不可或缺的一部分。
然而,尽管AI在今天看起来非常火爆,它的概念实际上已经存在了数十年。AI的发展历程可以追溯到20世纪50年代,当时人们就已经开始思考,机器是否能够模仿人类的思维并作出类似于人类的决策。今天,随着计算能力的飞跃和大数据的推动,AI的发展已经走到了我们想象的前沿。
二、人工智能发展历程
接下来,我们将深入了解人工智能的历史背景,重点介绍它如何从最初的理论探索走向今天的广泛应用,其中一个重要的里程碑就是图灵测试,它是AI能否具备智能的重要标志之一。
1. 1950年:图灵测试的提出
艾伦·图灵(Alan Turing)是AI领域的先驱之一。他在1950年提出了一个著名的问题:“机器能思考吗?”在他的论文《计算机器与智能》中,图灵提出了一种方法来检验机器是否具有智能,这就是后来被称为 “图灵测试” 的概念。

图灵测试的核心思想是,如果一个人通过文字交流无法分辨出是在和人类还是机器交谈,那么这台机器就可以被认为具备了“智能”。这虽然不是衡量机器智能的唯一标准,但它引发了人们对机器智能本质的深入思考。
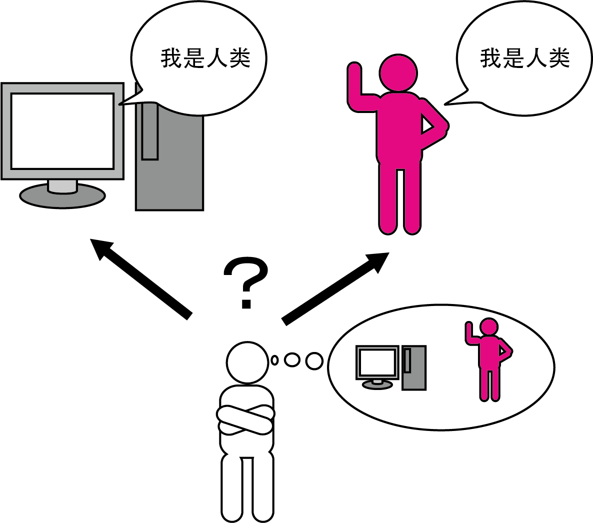
在图灵的时代,计算机的能力非常有限,连基本的对话模拟都无法实现。然而,图灵的思想极具前瞻性,它预示了人工智能领域未来的发展方向。时至今日,许多AI模型和聊天机器人(如GPT系列)都被用来测试是否能够通过图灵测试。
小实验
那么现在我们来做个小实验,大家来看看下面的两段对话,猜猜哪一段是由AI回复的,哪一段是由真人回复的。你认为A和B中谁是AI呢?请大家在评论区中扣出你的答案。
A:你这孩子,真的是让妈操碎了心!你看看你大姑大舅家的孩子,哪个不是早早就结婚了?人家都二胎了,你还连个对象都没有!你就天天忙什么啊?工作再忙,事业再拼,日子总得过吧?难道你打算一辈子单身?妈可不想老了连孙子都没得抱。说了多少次了,趁着年轻赶紧把婚事定下来,你不着急,妈替你急啊!今天我给你安排了几个相亲对象,都是人品好、家世清白的,你可别再挑了!一个是隔壁李阿姨家的外甥,在银行上班,工作稳当,长得也不错;还有一个是你同学介绍的,做IT的,收入高,就是有点宅;另外还有个是我朋友介绍的公务员,工作清闲,以后日子好过。你得听话啊!妈也是为了你好,再拖下去,你可不年轻了,等人都挑光了,剩下的你还看得上吗?趁现在条件还不错,好好相处,看看合不合适。你要是不回来见人,我可要亲自上门拉你回来!
B:孩子啊,你说你都多大了,咋还不着急结婚呢?你看看你大姑大舅家的孩子,人家一个个都结婚了,有的孩子都能打酱油了。你呢?整天就知道忙工作,工作能陪你一辈子呀?你也该为自己的终身大事考虑考虑了。你别总觉得自己还年轻,时间过得可快了,一晃你就成老姑娘了。我和你爸都为你着急,我们也想早点抱外孙啊。赶紧回家来,别在外面瞎晃悠了。我给你安排了几个相亲对象,你去见见。别总是挑三拣四的,差不多就行了。人家条件也都不错,你就不能好好把握把握机会?你也该收收心了,别整天没个正形。结婚是一辈子的大事,你得重视起来。别等以后老了,一个人孤孤单单的,连个说话的人都没有。听妈的话,赶紧找个对象结婚吧。
让我们揭晓答案,事实上这两段都是由AI生成的,前者是Chatgpt,后者则是豆包。
2. 20世纪50-70年代:早期探索与挫折
在图灵提出测试后,AI开始成为一个正式的研究领域。20世纪50年代,随着计算机硬件的进步,研究人员开始尝试用机器解决数学难题、进行象棋对弈等简单任务。这个时期的一些经典成就是:
- 1956年,达特茅斯会议被认为是人工智能正式诞生的标志

- 1966年,ELIZA程序诞生,这是一个简单的对话系统,模仿心理医生的语气进行对话
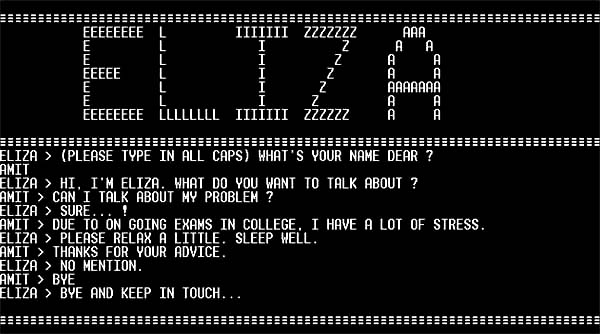
然而,由于技术受限和人们对AI能力的过高期望,到了70年代,AI研究进入了第一个“寒冬”,资金和兴趣的减少使得AI的发展速度放缓。
3. 20世纪80-90年代:知识推理与专家系统
随着计算机技术的进步,AI研究在80年代迎来了第二次热潮。这个时期的重点是专家系统,它们模拟人类专家的知识和推理过程,帮助解决特定领域的问题,例如医学诊断和金融分析。专家系统能够存储大量的知识库,并通过逻辑推理得出结论。
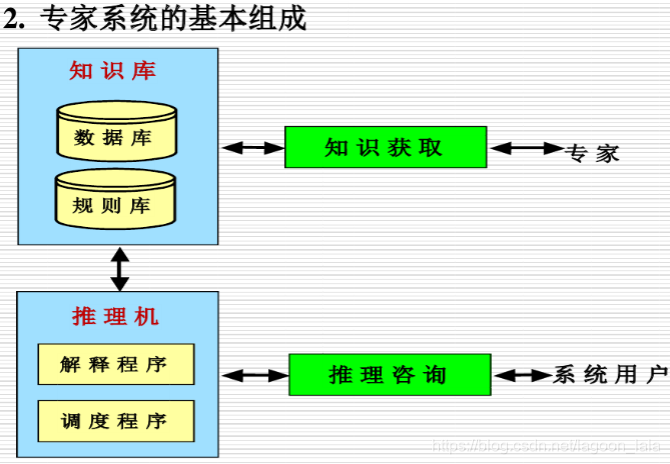
尽管专家系统在特定领域表现出色,但由于它们对特定领域知识的高度依赖,通用性较差,AI再次进入低谷期。
4. 21世纪初:机器学习与深度学习的崛起
真正推动AI复兴的,是机器学习和深度学习技术的发展。这些技术的关键在于它们依赖于数据和模型的训练能力,而不是预定义的规则。2006年,深度学习(Deep Learning)的兴起彻底改变了AI的发展方向。通过多层神经网络,AI不仅能够识别图像,还能够处理语音、文本等复杂数据。
在这些进步的背后,计算能力的飞跃和大数据的积累是不可忽视的推动力。如今,AI在图像识别、语音识别、自动驾驶、自然语言处理等领域取得了巨大的进步。

从图灵测试到现代AI,我们来总结一下,从图灵测试的提出,到如今AI已经能够模拟出复杂的语言对话、处理图像并作出智能决策,人工智能的发展历程充满了挑战与突破。图灵所提出的问题,至今仍然是AI领域的核心之一:机器是否能像人一样思考?接下来,我们将进一步深入探讨现代AI的核心技术和应用领域。
三、深度技术剖析
-
偏应用的前沿AI研究方向:
-
个性化医疗AI(Personalized Medicine AI)– 利用AI对患者进行个性化治疗方案的预测和生成。
-
自动驾驶感知与决策(Autonomous Driving Perception and Decision-Making)– 提升自动驾驶车辆的实时感知能力和复杂决策系统。
-
智能农业(AI in Precision Agriculture)– 利用AI优化农业生产中的作物监测、土壤分析和病虫害管理。
-
AI在药物发现中的应用(AI-Driven Drug Discovery)– 使用机器学习预测药物分子的活性,优化药物设计。
-
边缘计算中的AI(AI at the Edge)– 在低功耗设备上优化AI的部署,如智能家居、物联网等。
-
计算机视觉中的医疗图像分析(Medical Imaging in Computer Vision)– 通过深度学习识别和诊断医学影像中的病变。
-
对话系统与多轮对话生成(Conversational AI and Multi-turn Dialogue Generation)– 开发能够理解上下文并持续对话的高级聊天系统。
-
自然语言生成与总结(Natural Language Generation and Summarization)– 生成结构化文本和精准总结长文档的技术应用。
-
虚拟现实与AI融合(AI-Driven Virtual and Augmented Reality)– 利用AI在虚拟现实和增强现实中增强交互体验与环境生成。
-
网络安全中的AI(AI for Cybersecurity)– 研究AI如何用于入侵检测、恶意软件分析和网络威胁的实时响应。
-
-
偏理论的前沿AI研究方向:
-
对比学习(Contrastive Learning)– 利用对比目标在无监督学习中学习有意义的表征。
-
自监督学习(Self-Supervised Learning)–无需大规模人工标注数据进行高效学习的技术。
-
因果推理(Causal Inference in AI)– 探索机器学习中的因果关系,增强模型的推理和解释能力。
-
几何深度学习(Geometric Deep Learning)– 研究在非欧几里得空间(如图网络)中的深度学习应用。
-
神经符号学习(Neuro-Symbolic Learning)– 融合符号推理与神经网络来提升模型的通用性和推理能力。
-
元学习(Meta-Learning)– 研究如何让AI系统快速学习新任务或适应新环境。
-
神经架构搜索(Neural Architecture Search, NAS)– 自动化发现神经网络结构的理论和方法,以提升模型性能。
-
量子机器学习(Quantum Machine Learning)– 探索量子计算与机器学习的融合,推动解决复杂计算问题。
-
稀疏学习(Sparse Learning)– 在大规模数据集和模型中,研究如何利用稀疏性提升计算效率。
-
持续学习(Continual Learning)– 让AI系统在不遗忘旧任务的情况下,连续学习新任务。
-
1. 机器学习:数据驱动的智能
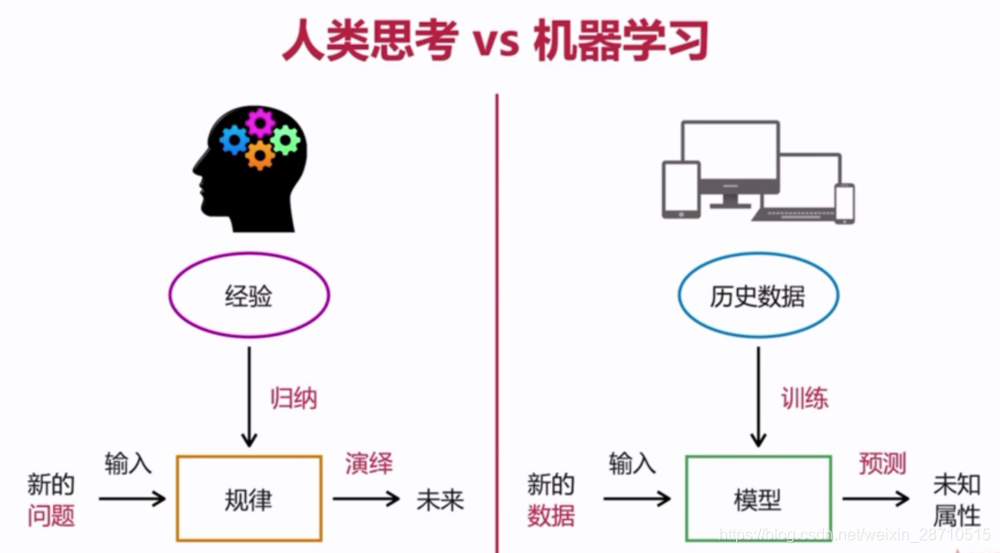
机器学习是人工智能的基础,通过大量的数据驱动让模型学习模式,优化决策过程。其核心思想是让机器在没有明确规则的情况下,从数据中自动学习。例如,股票价格预测,通过历史市场数据来寻找价格的趋势模式,而在医疗诊断中,机器学习可以通过大量的医学影像数据,找到特定疾病的特征。
-
线性回归 (Linear Regression) – 适用于连续型目标变量的预测,基于输入特征与目标变量之间的线性关系。最常用于经济预测、风险评估等。
-
逻辑回归 (Logistic Regression) – 用于二分类问题,通过估计事件的概率解决分类问题。广泛应用于医学诊断、垃圾邮件检测等领域。
-
支持向量机 (Support Vector Machines, SVM) – 通过寻找最优分隔超平面进行分类。可用于文本分类、图像分类等问题,特别适合高维数据。
-
K近邻算法 (K-Nearest Neighbors, KNN) – 通过比较新样本与训练集中最相似的K个邻居进行分类或回归,适合图像识别和推荐系统等领域。
-
决策树 (Decision Trees) – 通过一系列的决策规则进行分类或回归,具有良好的解释性,常用于信用评分、医疗诊断等领域。
-
随机森林 (Random Forests) – 集成多个决策树进行投票,具有更好的泛化能力,广泛应用于分类与回归问题,如金融预测、图像识别等。
-
梯度提升机 (Gradient Boosting Machines, GBM) – 通过逐步修正错误模型集成多个弱学习器,提升模型性能。适合电商推荐、风控等场景。
-
朴素贝叶斯 (Naive Bayes) – 基于贝叶斯定理的简单概率分类器,适用于文本分类、情感分析等任务,尤其在处理大规模文本数据时效果显著。
-
K均值聚类 (K-Means Clustering) – 用于无监督学习中的聚类问题,通过将样本划分为K个簇。广泛应用于市场细分、图像压缩等领域。
-
主成分分析 (Principal Component Analysis, PCA) – 用于降维,帮助在高维数据中找到重要的特征,常用于数据预处理和可视化。
-
长短期记忆网络 (Long Short-Term Memory, LSTM) – 一种改进的递归神经网络(RNN),擅长处理序列数据,如时间序列预测、自然语言处理。
-
卷积神经网络 (Convolutional Neural Networks, CNNs) – 主要用于处理图像和视频数据,广泛应用于图像分类、目标检测、面部识别等领域。
-
自编码器 (Autoencoder) – 一种用于无监督学习的神经网络模型,主要用于数据降维、去噪、生成模型等。
-
XGBoost (Extreme Gradient Boosting) – 一种基于梯度提升的高效实现,性能出色,常用于数据竞赛、结构化数据的回归和分类任务。
下面是一个简单的逻辑回归示例的结果展示:
相关逻辑回归演示代码:
or
2. 深度学习:模仿人类大脑的神经网络
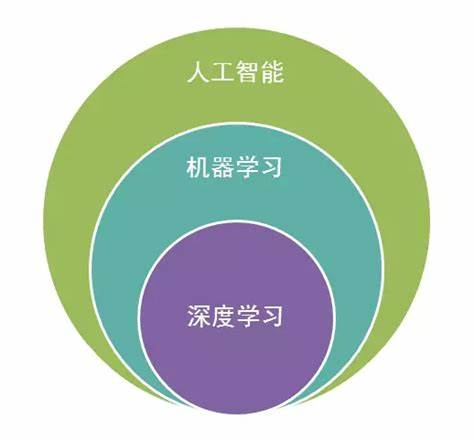
深度学习是机器学习的一个子集,采用的是人工神经网络的结构,特别擅长处理复杂的非线性问题。它通过层层抽象的方式,逐步从输入数据中提取特征。
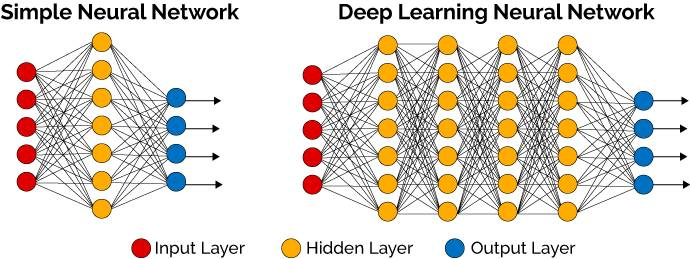
一个经典的例子就是卷积神经网络 (CNN),它专门用于处理图像数据。
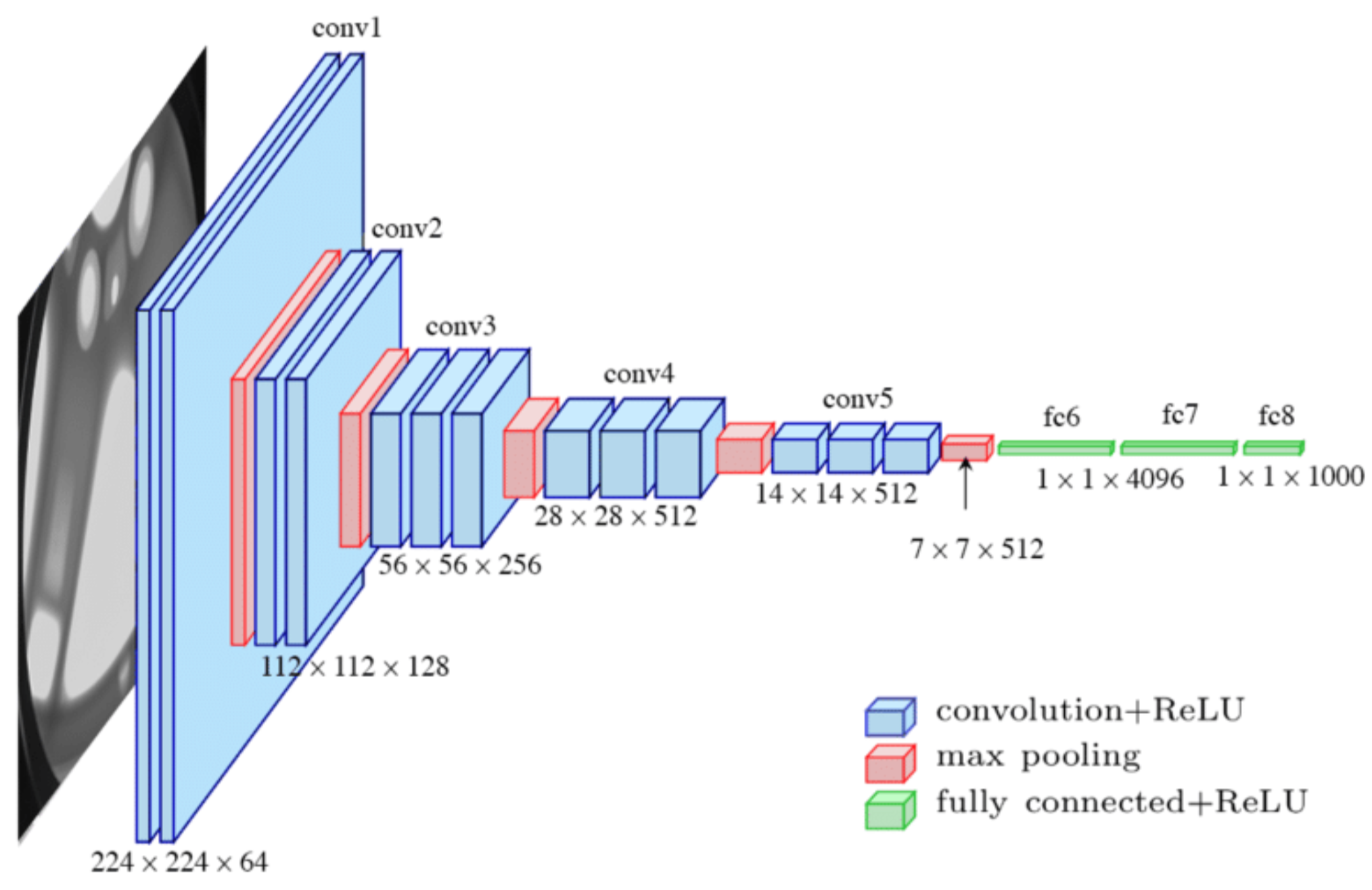
CNN的工作原理:CNN的核心是卷积层和池化层。卷积层通过卷积核扫描图像,提取低级特征如边缘、颜色等,而池化层则缩减数据的维度,保留重要信息。随着网络层数的增加,CNN可以提取更高级的特征,如物体形状、结构等。
举个例子,我们使用手写数字识别 (MNIST) 数据集,通过CNN来让模型识别手写数字。这个过程包括了输入图像通过多个卷积层和池化层的处理,最后通过全连接层进行分类。通过这种结构,深度学习能够实现复杂的任务,比如图像分类、语音识别等。
四、热门前沿技术与研究方向(部分)
-
自然语言处理 (NLP) – Transformer
自然语言处理让机器能够理解和生成人类语言,背后的技术尤其复杂,因为语言涉及语法、语义、上下文等多层次的信息处理。一个关键的突破是Transformer模型,它利用自注意力机制(Self-Attention)来处理文本中的长距离依赖关系。
-
Transformer与BERT:Transformer模型的核心在于自注意力机制,它能够同时关注输入文本的不同部分,从而捕捉长文本中的复杂依赖关系。BERT是基于Transformer的双向模型,它能够同时关注词汇的前后文信息,擅长文本分类、情感分析等任务。比如,当我们要对一篇文章进行情感分析时,BERT可以很好地捕捉到文章的整体语义。
-
GPT模型:与BERT不同,GPT专注于文本生成。GPT系列模型在对话、写作助手中表现出色,它能够生成流畅、连贯的文本。通过大量的预训练,GPT掌握了复杂的语言结构,并能够在给定提示下生成高质量的文章。
-
-
生成式对抗网络 (GAN)
生成式对抗网络是一种让AI生成数据的技术。GAN由两个主要部分组成:生成器和判别器。生成器负责生成假数据,而判别器则尝试区分真假数据。两者之间相互对抗,生成器通过不断改进,生成的假数据越来越像真实数据。
应用:Deepfake:Deepfake技术是GAN的一个典型应用,它利用生成器生成高度逼真的人脸视频。这项技术已经引发了广泛的关注,因为它可以以假乱真地生成虚假的人物视频,带来了隐私与伦理方面的挑战。
GAN还可以用于图像修复、艺术创作等领域。例如,GAN可以修复模糊的照片,将其还原为高分辨率图像;它还可以生成完全虚拟的艺术作品,展示AI在创意领域的巨大潜力。
-
自监督学习与多模态模型
自监督学习是近年来的一个重要突破,它能够在没有大量标注数据的情况下,通过未标注的数据进行学习。这大大减少了对人工标注的依赖,尤其在数据标注成本高的领域(如医学影像)中非常有用。
多模态模型:多模态模型能够同时处理多个不同类型的数据,如图像和文本。例如,CLIP和DALL·E这样的模型能够从文本描述生成图像,或从图像生成文本描述。这类模型利用跨模态的理解,使得AI可以处理更加复杂、多样化的任务。
-
计算机视觉:赋予机器“看见”能力 – Yolo
计算机视觉是AI的一个重要分支,它的任务是让机器能够理解和处理图像和视频。除了我们前面提到的CNN外,计算机视觉技术在对象检测、图像分割、姿态估计等领域有广泛应用。
对象检测与YOLO模型:对象检测是计算机视觉的关键任务,目标是找到图像中的物体,并标注它们的位置。YOLO模型(You Only Look Once)是一个实时对象检测的模型,它能够在一次前向传播中识别图像中的多个物体,并输出它们的边界框和类别标签。
图像分割与Mask R-CNN:图像分割比对象检测要求更高,它不仅要检测出物体的位置,还要精确地分割出物体的边界。Mask R-CNN是一种常见的图像分割模型,它能够为每个像素点分配类别标签,从而实现精确的图像分割。
这些技术广泛应用于自动驾驶、医疗影像分析、安防监控等领域。举例来说,自动驾驶汽车通过计算机视觉可以识别前方的行人、车辆和交通标志,从而进行合理的路线规划和安全操作。
五、AI学习与实践平台
-
介绍:Hugging Face是一个开源社区和平台,提供了大量预训练的NLP模型。
应用:学生可以利用该平台的模型进行文本分类、翻译、文本生成等任务。
资源:介绍如何在Hugging Face上使用Transformers库,以及平台提供的各种模型和工具。
-
介绍:Kaggle是一个数据科学竞赛平台,提供了丰富的数据集、代码示例和教程。
应用:学生可以通过Kaggle参与竞赛,学习如何解决实际问题,如图像分类、数据分析等。
资源:介绍Kaggle的Notebook环境、论坛讨论区和公开数据集。
-
介绍:Google Colab是一个免费的在线计算平台,支持GPU加速,方便AI模型的开发与训练。
应用:学生可以利用Colab进行深度学习模型的训练和实验,无需本地配置复杂的环境。
资源:展示如何使用Colab进行模型训练,如CNN或RNN的训练过程。
-
介绍:Papers with Code是一个将AI研究论文与实际代码实现相结合的平台。
应用:学生可以通过该平台学习最新的AI研究成果,并直接获取相关代码。
资源:展示如何在该平台上查找最新的AI论文和相关的代码实现。