说明:这是一个基础的关于机器学习的入门介绍,同样是笔者在担任学校AI社团社长时为社团精心准备的每周讲座之一,在讲座后笔者重新整理了一遍,希望通过博客的方式分享给更多的人
大家好!今天要带大家认识的是机器学习。机器学习是一种让计算机能够从数据中自动找到规律并完成任务的方法,比如根据历史电影推荐新电影、根据语音识别并回答问题等。我们今天的目标是先理解机器学习的完整流程,再详细了解一些重要概念和常见模型,让大家对机器学习有一个系统的初步认识。
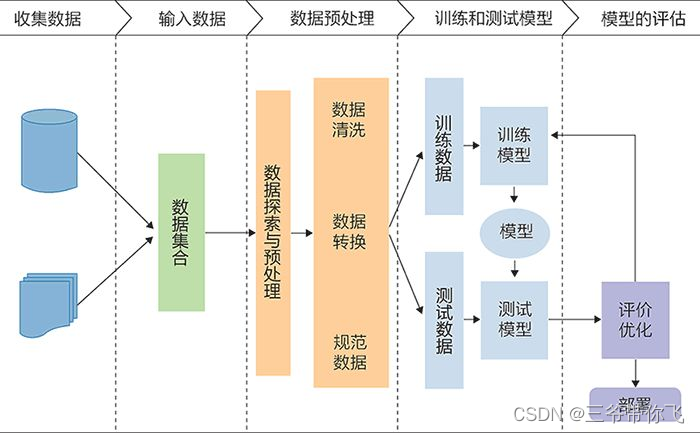
一、机器学习的完整流程
-
要训练出一个有效的机器学习模型,通常会遵循以下步骤:
- 定义问题:首先明确希望机器学习模型完成什么任务,比如分类还是预测。
- 收集和准备数据:从数据集中提取特征和标签。特征是模型的输入,而标签是期望的输出。
- 数据预处理:通常包含清理数据、处理缺失值、进行特征缩放等。特征缩放可以让模型训练更快,尤其是涉及距离计算的模型。
- 选择模型:根据任务需求,选择适合的模型,如线性回归用于数值预测,决策树用于分类问题等。
- 定义损失函数:损失函数用来衡量模型的预测结果和真实值之间的误差。我们希望这个误差尽量小。
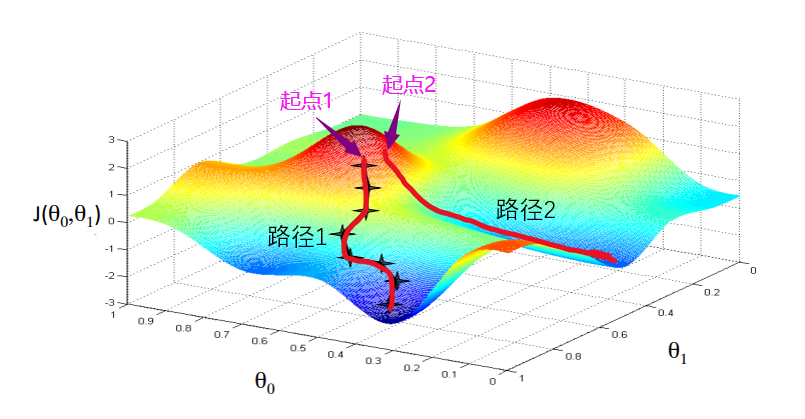
- 训练模型:通过反复调整模型的参数(如权重和偏置)来最小化损失函数的值。常用的方法是梯度下降。
- 评估模型:使用测试数据集评估模型的效果,查看模型在新数据上的表现。
- 调优与改进:通过超参数调优和交叉验证等方法进一步优化模型。
二、机器学习的重要概念与参数
1. 损失函数(Loss Function)
-
在模型训练过程中,损失函数是一个非常重要的概念,因为它定义了模型“做错了多少”,是模型优化的目标。
-
损失函数衡量了模型预测值与实际值之间的差距。模型的目标就是找到一组参数,使得损失函数的值尽可能小。换句话说,损失函数告诉我们模型的错误程度,我们希望通过训练减少这些错误。
常见的损失函数
- 不同的任务会用不同的损失函数,今天我们介绍几个经典的例子。
- 均方误差(MSE):
-
定义:用于回归问题的损失函数,计算预测值与真实值之间差值的平方平均值。公式为:
\[MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2\]其中,$y_i$ 是真实值,$\hat{y}_i$ 是模型的预测值。
-
为什么用平方:平方可以让大的误差比小的误差更显著,这样模型在训练时会优先减少较大的误差,从而提高整体效果。
-
- 交叉熵损失:
-
定义:交叉熵损失常用于分类问题,尤其是二分类或多分类。公式为:
\[L = -\frac{1}{n} \sum_{i=1}^{n} \left( y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right)\]其中 $y_i$ 为真实标签(0或1),$\hat{y}_i$ 为预测的概率。
-
含义:交叉熵测量了真实分布与预测分布之间的差异。它可以逼迫模型预测接近真实分布的概率,从而更准确地分类。
-
代码示例:计算均方误差和交叉熵损失
- 我们用 Python 中的
sklearn实现简单的损失函数计算:
from sklearn.metrics import mean_squared_error, log_loss
import numpy as np
# 模拟数据
y_true = [1, 0, 1, 1, 0]
y_pred_reg = [0.9, 0.2, 0.8, 0.7, 0.3] # 回归预测值
y_pred_class = [0.9, 0.1, 0.8, 0.6, 0.2] # 分类预测概率
# 计算均方误差
mse = mean_squared_error(y_true, y_pred_reg)
print("均方误差 MSE:", mse)
# 计算交叉熵损失
cross_entropy = log_loss(y_true, y_pred_class)
print("交叉熵损失:", cross_entropy)
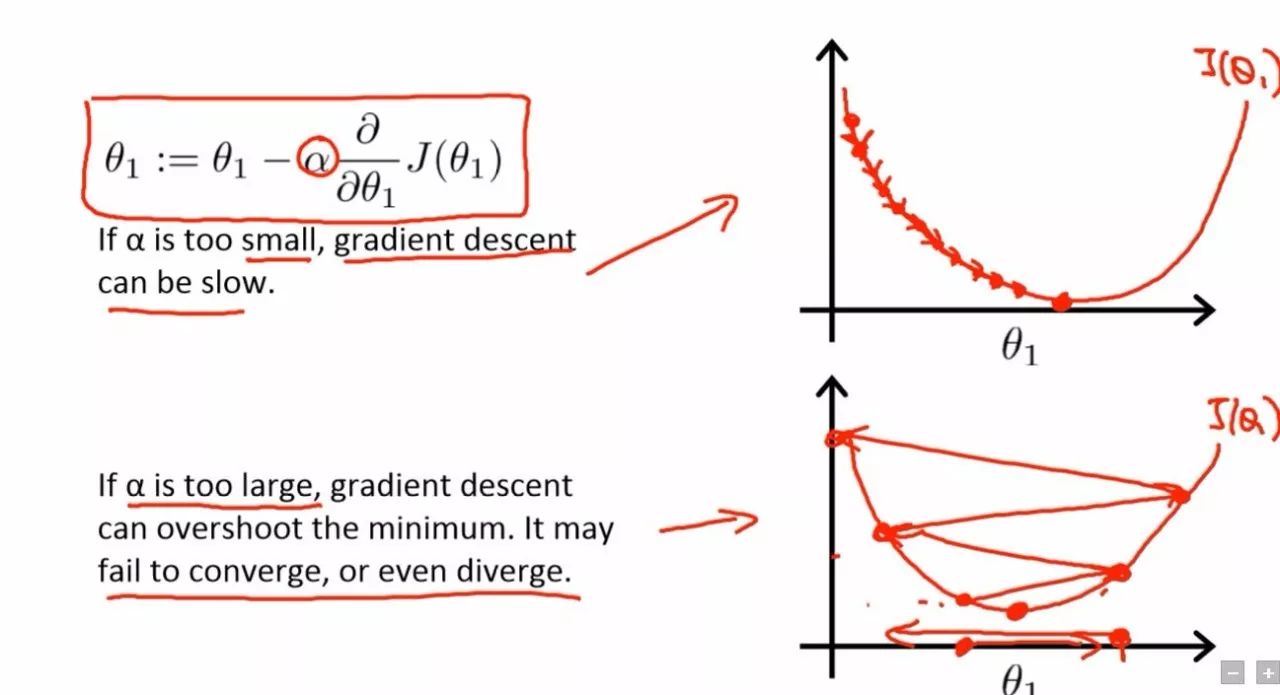
2. 学习率(Learning Rate)
- 学习率是控制模型每次更新参数时步伐大小的超参数。每次训练时,模型根据损失函数的梯度更新参数,以减少误差。学习率决定了在每次更新中,模型应移动多大步。
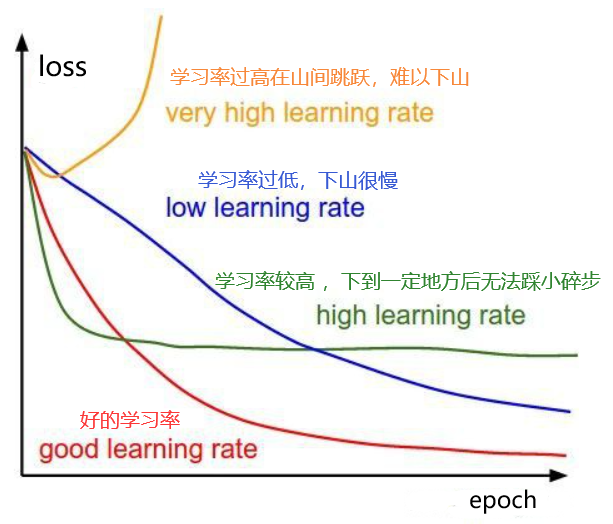
为什么需要学习率?
-
模型参数更新的大小直接影响模型的训练效果:
-
如果步伐太大,模型可能跳过最佳解,无法收敛,导致训练不稳定。
-
如果步伐太小,模型的更新非常缓慢,可能需要较长时间才能收敛,甚至陷入局部最优解。
-
学习率的选择
-
选择合适的学习率通常是训练机器学习模型时的重要步骤:
-
固定学习率:在整个训练过程中使用固定的学习率,适合较简单的模型。
-
学习率调度(Scheduler):训练开始时学习率较大,随着训练进展逐渐降低,有助于在开始时快速靠近最优点,后期精细调整。
-
自适应学习率优化算法:如 Adam 和 RMSprop,会根据每个参数的梯度自动调整学习率,使训练更稳定高效。
-
代码示例:使用不同的学习率
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib.pyplot as plt
# 生成更复杂的示例数据(带有噪声的线性数据)
np.random.seed(42)
X = np.linspace(1, 10, 100).reshape(-1, 1)
y = 3 * X.squeeze() + np.random.randn(100) * 2 # 加入随机噪声
# 创建两种学习率的模型
model_high_lr = SGDRegressor(learning_rate='constant', eta0=0.5, max_iter=1, tol=None)
model_low_lr = SGDRegressor(learning_rate='constant', eta0=0.1, max_iter=1, tol=None)
# 初始化损失记录
loss_high_lr, loss_low_lr = [], []
# 模拟逐步迭代1000次并记录损失
for i in range(1000):
model_high_lr.partial_fit(X, y) # 使用 partial_fit 来控制迭代步数
model_low_lr.partial_fit(X, y)
# 计算当前迭代的损失
loss_high_lr.append(mean_squared_error(y, model_high_lr.predict(X)))
loss_low_lr.append(mean_squared_error(y, model_low_lr.predict(X)))
# 输出最终的模型参数
print("高学习率的模型参数:", model_high_lr.coef_, model_high_lr.intercept_)
print("低学习率的模型参数:", model_low_lr.coef_, model_low_lr.intercept_)
# 可视化损失变化
plt.plot(loss_high_lr, label="High Learning Rate (0.5)")
plt.plot(loss_low_lr, label="Low Learning Rate (0.1)")
plt.xlabel("Iterations")
plt.ylabel("Mean Squared Error")
plt.title("Loss Convergence with Different Learning Rates")
plt.legend()
plt.show()
3. 正则化(Regularization)
- 正则化是一种控制模型复杂度的方法,防止模型过度拟合训练数据。正则化通过惩罚项的方式,让模型的参数尽可能小,从而降低复杂度,提高模型的泛化能力。
为什么需要正则化?
- 在训练过程中,如果模型的参数值过大,可能导致模型对训练数据过度拟合,从而在新数据上表现不佳。正则化项会惩罚较大的参数值,避免模型在训练数据中“记住”噪声,提高其在测试数据上的表现。
常见的正则化方法
-
L1 正则化(Lasso 回归):
L1 正则化通过在损失函数中加入一个基于权重绝对值的惩罚项,鼓励模型参数向零靠拢。其损失函数形式为:
\[L = \text{原损失} + \lambda \sum |w|\]其中 $\lambda$ 是正则化系数,用于控制惩罚的强度。
-
具体作用:L1 正则化会将一些特征的权重完全压缩到零,即忽略这些特征的影响。这样可以在数据特征较多的情况下,让模型仅保留最重要的特征,从而使模型更简单、易解释。
-
为什么会产生稀疏性:因为 L1 正则化项是权重的绝对值,当优化时,它倾向于让部分权重直接为零,以达到最小化损失的效果。
-
适用场景:L1 正则化适用于高维数据集,尤其是那些包含许多冗余特征或噪声特征的场景。通过筛选出重要特征,L1 正则化可以让模型更高效、更易于解释。
示例:在特征选择任务中,L1 正则化可以去除不相关的特征,帮助我们找到对模型影响最大的特征。
-
-
L2 正则化(Ridge 回归):
L2 正则化通过在损失函数中加入权重平方的惩罚项,使权重的值更小且稳定。其损失函数形式为:
\[L = \text{原损失} + \lambda \sum w^2\]其中 $\lambda$ 仍是正则化系数。
-
具体作用:L2 正则化鼓励所有特征的权重更接近于零,但不会完全为零。它会“缩小”每个特征的权重,使得模型对所有特征的依赖较为均匀,不至于过度依赖少数特征。
-
不产生稀疏性:L2 正则化的平方惩罚项会使得权重逐渐接近于零,但不会完全为零。这意味着模型仍然会利用所有的特征。
-
适用场景:L2 正则化适用于数据特征都具有重要性或相互间具有相关性的情况,比如很多变量彼此存在线性相关性(共线性),L2 正则化能帮助模型稳定训练,降低方差。
示例:在回归分析中,L2 正则化适用于多重共线性问题严重的数据,帮助模型避免对某个特征的过度依赖。
-
-
Elastic Net 正则化:
Elastic Net 正则化结合了 L1 和 L2 正则化的优点,使用一个同时包含权重绝对值和权重平方的惩罚项。其损失函数形式为:
\[L = \text{原损失} + \alpha \lambda \sum |w| + (1 - \alpha) \lambda \sum w^2\]其中 $\lambda$ 是正则化强度,$\alpha$ 控制 L1 和 L2 正则化的相对权重。
-
具体作用:Elastic Net 保持了 L1 的稀疏性特点(去除不重要的特征),同时也利用了 L2 的缩减效果(降低权重大小)。这样可以在去除冗余特征的同时,保留对所有特征的适度依赖。
-
适用场景:Elastic Net 正则化适合特征数量多且彼此高度相关的数据,尤其在高维数据中效果尤佳,因为它既能筛选特征又能减少模型复杂度。
示例:在文本分类或基因数据分析等高维数据应用中,Elastic Net 正则化可以有效控制模型复杂度,提升模型的泛化性能。
-
小结
- L1 正则化:通过绝对值惩罚项实现稀疏性,使部分特征权重趋向于零,适用于特征多、需要筛选重要特征的任务。
- L2 正则化:通过平方惩罚项缩小权重值,适合特征重要性接近或彼此相关的任务,不产生稀疏性。
- Elastic Net 正则化:结合 L1 和 L2 的优点,适合高维数据,尤其适用于需要控制模型复杂度并同时保留重要特征的任务。
- 通过这三种正则化方法的详细解释,我们可以灵活应用正则化来调节模型复杂度,增强模型的泛化能力和稳定性。
代码示例:正则化在模型中的应用
from sklearn.linear_model import Ridge, Lasso
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子,生成数据
np.random.seed(42)
X = np.random.rand(50, 10) # 生成10个特征,其中3个为有效特征,其余为噪声特征
y = 3 * X[:, 0] + 2 * X[:, 1] - X[:, 2] + np.random.randn(50) * 0.1
# 初始化不同正则化强度的模型
ridge_model = Ridge(alpha=1.0)
lasso_model = Lasso(alpha=0.1)
# 拟合模型
ridge_model.fit(X, y)
lasso_model.fit(X, y)
# 输出模型系数
print("Ridge回归模型系数:", ridge_model.coef_)
print("Lasso回归模型系数:", lasso_model.coef_)
# 可视化系数对比
plt.figure(figsize=(10, 6))
plt.plot(ridge_model.coef_, 'o', label="Ridge Coefficients (L2)")
plt.plot(lasso_model.coef_, 'x', label="Lasso Coefficients (L1)")
plt.hlines(0, 0, len(ridge_model.coef_), colors='gray', linestyles='dashed')
plt.xlabel("Feature Index")
plt.ylabel("Coefficient Value")
plt.title("Comparison of Ridge and Lasso Coefficients")
plt.legend()
plt.show()
4. 批量大小(Batch Size)
-
在训练神经网络时,批量大小指的是在每次参数更新时所用的数据量。批量大小决定了模型每次计算梯度时的数据样本数。通常有以下三种更新方式:
- 全批量梯度下降(Batch Gradient Descent):使用所有数据计算梯度并更新模型参数。适用于数据量较小的情况,但计算开销大。
- 小批量梯度下降(Mini-batch Gradient Descent):每次更新时使用固定大小的部分数据。能在速度和稳定性之间取得平衡,是最常用的方法。
- 随机梯度下降(Stochastic Gradient Descent, SGD):每次更新仅使用一个样本。计算效率高,但收敛稳定性较差,适合大数据集。
为什么需要控制批量大小?
- 批量大小对模型的训练速度、稳定性和泛化能力都有影响:
-
小批量有助于更快更新参数,能较快找到较优解,但会引入一些噪声。
-
大批量更新更为稳定,但可能会增加训练时间,且对模型泛化能力有所影响。
-
如何选择批量大小?
- 小批量(16、32、64 等)适合绝大多数深度学习任务,能在稳定性和速度之间取得良好平衡。
- 大批量(128、256 甚至更大)在分布式训练中更常用,但要确保模型不容易陷入局部最优解。
代码示例:使用不同批量大小的效果(以深度学习为例)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
# 生成模拟数据
np.random.seed(42)
X = np.random.rand(1000, 10).astype(np.float32)
y = np.round(np.random.rand(1000)).astype(np.float32)
# 转换为张量
X_tensor = torch.tensor(X)
y_tensor = torch.tensor(y).view(-1, 1)
# 创建数据集和数据加载器
dataset = TensorDataset(X_tensor, y_tensor)
# 定义简单的神经网络模型
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 32)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.sigmoid(x)
return x
# 创建模型
model = SimpleNet()
# 损失函数
criterion = nn.BCELoss()
# 不同的学习率和批量大小设置
learning_rate = 0.01
# 小批量训练
small_batch_loader = DataLoader(dataset, batch_size=32, shuffle=True)
optimizer_small = optim.SGD(model.parameters(), lr=learning_rate)
print("小批量训练:")
for epoch in range(5):
for batch_idx, (data, target) in enumerate(small_batch_loader):
optimizer_small.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer_small.step()
if batch_idx % 10 == 0: # 每10个批次打印一次
print(f'Epoch {epoch+1}, Batch {batch_idx}, Loss: {loss.item():.4f}')
# 重新初始化模型参数
model = SimpleNet()
optimizer_large = optim.SGD(model.parameters(), lr=learning_rate)
# 大批量训练
large_batch_loader = DataLoader(dataset, batch_size=128, shuffle=True)
print("\n大批量训练:")
for epoch in range(5):
for batch_idx, (data, target) in enumerate(large_batch_loader):
optimizer_large.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer_large.step()
if batch_idx % 5 == 0: # 每5个批次打印一次
print(f'Epoch {epoch+1}, Batch {batch_idx}, Loss: {loss.item():.4f}')
总结:学习率、正则化和批量大小的影响
- 学习率:控制模型参数更新步伐,学习率过大会导致训练不稳定,过小则收敛缓慢。
- 正则化:通过惩罚项减少过拟合,适用于防止模型对训练数据的过度记忆。
- 批量大小:决定每次更新所用的样本数,影响模型的收敛速度和稳定性。
- 这些参数和超参数在机器学习中起着至关重要的作用,不仅直接影响模型的表现,还决定了训练过程的效率。掌握这些概念可以帮助我们更好地调试和优化模型。
三、常见模型
在明确了损失函数后,我们来学习几种常见的机器学习模型。
1. 线性回归:用于数值预测
概念
-
线性回归是一种非常经典的机器学习算法,用于预测数值。假设变量之间存在线性关系,我们可以用一条直线(在多维空间则是一个平面或超平面)来描述输入变量和目标变量的关系。
-
例如,假设我们要预测房价,可以认为房价与房屋面积之间存在近似的线性关系,即面积越大,房价可能越高。线性回归可以通过“学习”找到这条直线,使得预测的房价尽量接近真实的房价。
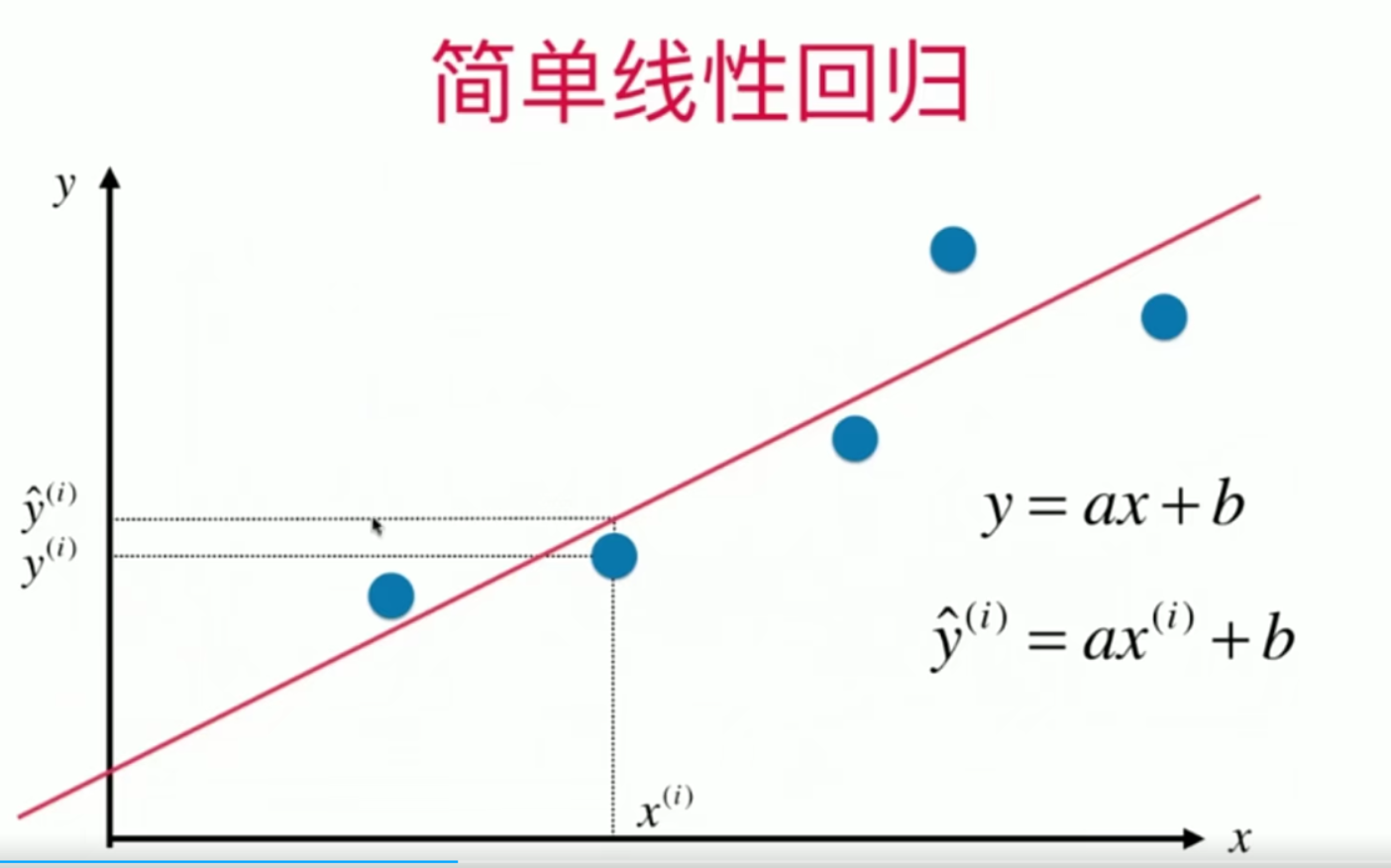
模型公式
-
在一元线性回归中,模型公式为:
\[y = wx + b\]其中:
- $y$ 表示预测的目标值(例如房价)。
- $x$ 表示输入特征(例如房屋面积)。
- $w$ 是权重或斜率,决定了直线的倾斜程度。
- $b$ 是偏置(也叫截距),决定了直线在 y 轴上的位置。
-
如果有多个特征(即多元线性回归),公式会变为:
\[y = w_1 x_1 + w_2 x_2 + \cdots + w_n x_n + b\]其中 $x_1, x_2, \ldots, x_n$ 表示不同的特征, $w_1, w_2, \ldots, w_n$ 是对应的权重。
优化目标和损失函数
- 线性回归的目标是找到一组最优的 $w$ 和 $b$,使得预测值 $y$ 与真实值之间的误差最小。这里的误差是通过损失函数来衡量的。
-
损失函数:在回归任务中,我们常用均方误差(MSE)作为损失函数,其定义为:
\[MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2\]其中:
- $n$ 是数据的总样本数。
- $y_i$ 是第 $i$ 个样本的真实值。
- $\hat{y}_i$ 是第 $i$ 个样本的预测值(即 $\hat{y}_i = w x_i + b$)。
-
优化目标:我们希望通过调整 $w$ 和 $b$ 的值,使均方误差最小化,从而使预测值尽可能接近真实值。
-
梯度下降法:一种常见的优化方法是梯度下降。梯度下降通过迭代不断调整 $w$ 和 $b$,使得损失函数逐步减小,直到达到最小值附近。梯度下降的更新规则为:
\[w = w - \alpha \frac{\partial MSE}{\partial w}\] \[b = b - \alpha \frac{\partial MSE}{\partial b}\]其中 $\alpha$ 是学习率,决定了每次更新的步伐大小。
代码示例:使用 sklearn 实现线性回归
- 我们可以使用 Python 的
sklearn库快速实现线性回归。以下示例中,我们创建一些简单的数据来训练和测试模型。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 生成模拟数据
# X 表示房屋面积 (单位:平方米),y 表示房价 (单位:万元)
np.random.seed(42)
X = np.random.rand(100, 1) * 100 # 随机生成 0 到 100 的面积
y = 3 * X + 5 + np.random.randn(100, 1) * 10 # 假设房价和面积的线性关系,加上一些噪声
# 可视化数据
plt.scatter(X, y, color='blue', label='真实数据')
plt.xlabel('房屋面积 (平方米)')
plt.ylabel('房价 (万元)')
plt.title('房屋面积与房价的关系')
plt.legend()
plt.show()
# 使用 sklearn 训练线性回归模型
model = LinearRegression()
model.fit(X, y)
# 预测结果
y_pred = model.predict(X)
# 计算均方误差
mse = mean_squared_error(y, y_pred)
print(f"均方误差 MSE: {mse:.2f}")
# 可视化回归直线
plt.scatter(X, y, color='blue', label='真实数据')
plt.plot(X, y_pred, color='red', label='预测直线')
plt.xlabel('房屋面积 (平方米)')
plt.ylabel('房价 (万元)')
plt.title('线性回归拟合结果')
plt.legend()
plt.show()
# 输出回归模型的参数
print(f"回归系数(权重) w: {model.coef_[0][0]:.2f}")
print(f"截距 b: {model.intercept_[0]:.2f}")
代码分析
- 我们首先使用随机生成的面积(0-100 平方米)和房价数据(假设房价和面积存在线性关系,并加入噪声)。
model.fit(X, y):通过sklearn的LinearRegression类训练模型,模型会自动找到最佳的 ( w ) 和 ( b ) 使得均方误差最小。model.predict(X):使用训练好的模型预测房价。mean_squared_error(y, y_pred):计算预测结果和真实房价之间的均方误差,衡量模型的拟合效果。
小结与扩展
- 为什么选择均方误差?
- 均方误差会将大的误差放大,使模型更关注大误差的样本。这种特性在回归任务中非常有用,可以让模型尽量减少极端误差。
- 其他损失函数
- 绝对误差(MAE):计算每个预测误差的绝对值并取平均。这种损失函数不那么关注极端误差,因此对于一些异常点较多的情况更稳健。
- Huber损失:结合了均方误差和绝对误差的优点,适合于数据中含有少量异常值的情况。
- 应用场景
- 线性回归在很多场景下非常有用,比如房价预测、市场需求预测等。虽然简单,但它为后续更复杂的机器学习模型打下了基础。
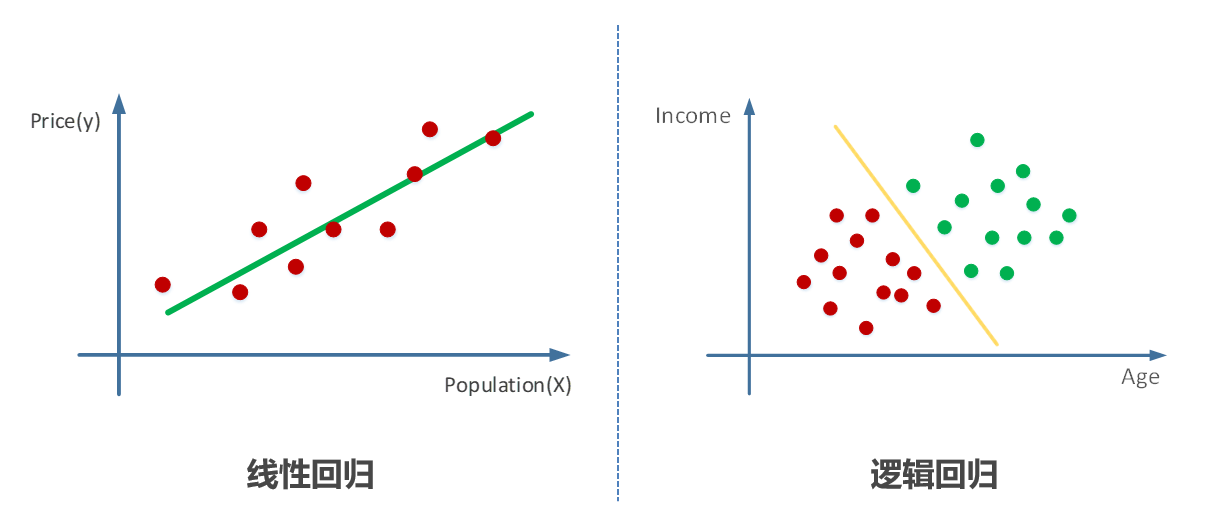
2. 逻辑回归:用于分类问题
概念
-
逻辑回归是一种分类模型,用于预测某个事件的发生概率。例如,在垃圾邮件分类中,逻辑回归模型可以判断一封邮件是否属于垃圾邮件。虽然名称中带有“回归”,但逻辑回归是分类算法,因为其输出是一个类别概率,而不是连续数值。
-
逻辑回归本质上是通过计算概率来完成分类任务。其目标是估计输入特征 $x$ 属于某一类别的概率,通常为 0 到 1 之间。然后通过设定一个阈值(通常为 0.5),将概率映射为某个类别(例如,1 表示垃圾邮件,0 表示非垃圾邮件)。
逻辑回归的完整流程
- 我们可以将逻辑回归的整个流程分解为几个关键步骤,逐步分析每一步的作用和目的。
1. 数据输入:准备特征和标签
-
在开始训练逻辑回归模型之前,我们需要有数据集,其中包含输入特征和目标标签。
-
输入特征 $x$:模型的输入数据。例如,在垃圾邮件分类任务中,输入特征可以是邮件的关键词、发件人等信息。
-
目标标签 $y$:模型的真实输出。例如,1 表示垃圾邮件,0 表示非垃圾邮件。
示例: 假设我们要预测一个学生是否通过考试,输入特征是学习时间 $x$,目标标签 $y$ 为 1(通过考试)或 0(未通过考试)。
-
2. 特征与权重的线性组合:初始输出
-
逻辑回归的核心是将输入特征与一组权重 $w$ 和偏置 $b$ 结合,通过线性组合生成一个初始输出。其公式为:
\[z = w \cdot x + b\]其中:
- $w$ 表示权重向量,控制每个特征在模型中的重要性。
- $b$ 表示偏置项,帮助模型更好地拟合数据。
- $z$ 表示线性组合的输出,这个输出值会作为分类判断的基础。
示例: 假设我们有学习时间 $x = 5$ 小时,权重 $w = 2$,偏置 $b = -3$,则: 得到的 $z = 7$ 表示一个线性输出。
\[z = 2 \times 5 - 3 = 10 - 3 = 7\]理解这个输出:
- 这个 $z$ 值并不是事件发生的概率。它只是一个实数值,用于描述模型对样本的初步评估。为了将这个输出转化为“是否会发生”的判断,我们需要进一步处理。
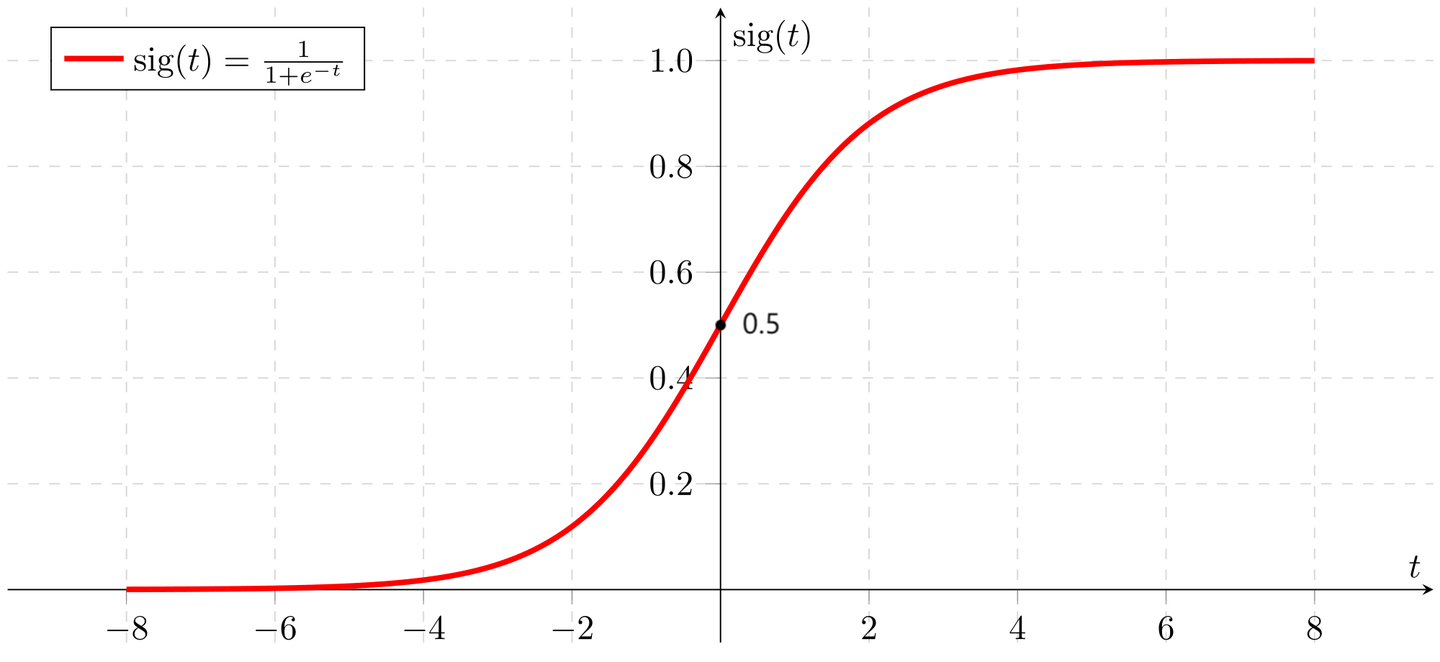
3. 将线性输出转换为概率:Sigmoid 函数的引入
-
为了将 $z$ 转换为事件发生的概率,我们需要将其映射到 0 到 1 之间。这是因为概率的定义是 0 到 1 之间的数值,表示事件发生的可能性。
Sigmoid 函数的定义: Sigmoid 函数是一种 S 形函数,可以将任意的实数 $z$ 转换为 0 到 1 之间的值。其公式为:
\[\sigma(z) = \frac{1}{1 + e^{-z}}\]其中:
- $z$ 是线性输出的值。
- $e$ 是自然对数的底数(约为 2.718)。
为什么使用 Sigmoid 函数?
- 当 $z$ 趋向正无穷时,Sigmoid 函数的值接近 1,表示事件几乎肯定会发生。
- 当 $z$ 趋向负无穷时,Sigmoid 函数的值接近 0,表示事件几乎不可能发生。
- 当 $z = 0$ 时,Sigmoid 函数的值为 0.5,表示事件发生与否的概率相等。
示例: 对于上面的例子,若 $z = 7$,则:
\[\sigma(7) = \frac{1}{1 + e^{-7}} \approx 0.999\]表示事件发生的概率非常高(接近 1),因此我们可以预测学生有很大可能通过考试。
4. 概率转换为分类结果:应用决策阈值
- 经过 Sigmoid 函数转换后,我们得到一个事件发生的概率值。为了将概率转换为具体的分类结果,我们通常引入一个决策阈值。
- 常见的做法是将 0.5 作为阈值:
- 若 $P(y=1 \vert x) \geq 0.5$,则预测 $y = 1$(事件发生,例如“通过考试”)。
- 若 $P(y=1 \vert x) < 0.5$ ,则预测 $y = 0$(事件不发生,例如“未通过考试”)。
示例: 对于前面的例子,计算得到的概率 $P(y=1 \vert x) \approx 0.999$,因此模型预测学生会通过考试。
总结:
- 经过决策阈值的应用,我们将连续的概率值转换为具体的分类标签,这样便完成了分类任务。
- 常见的做法是将 0.5 作为阈值:
完整的过程总结
- 数据输入:提供特征 $x$ 和标签 $y$。
- 线性组合输出:计算 $z = w \cdot x + b$,得到线性输出。
- Sigmoid 函数转换:使用 Sigmoid 函数将 $z$ 转换为概率 $P(y=1 \vert x)$。
- 决策阈值:根据阈值将概率转化为分类结果 $y = 1$ 或 $y = 0$。
优化目标:交叉熵损失函数
-
在逻辑回归中,我们使用交叉熵损失来衡量预测值和真实值之间的误差。交叉熵损失函数的公式为:
\[L = -\frac{1}{n} \sum_{i=1}^{n} \left( y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right)\]其中:
- $y_i$ 是第 $i$ 个样本的真实标签,取值为 0 或 1。
- $\hat{y}_i$ 是第 $i$ 个样本的预测概率。
-
交叉熵损失函数可以理解为一种最大化预测概率的手段。损失值越小,表示模型的预测越接近真实标签,模型性能越好。
代码示例:使用 sklearn 实现逻辑回归
- 为了演示逻辑回归的使用,我们用一个二分类的示例数据集,来判断某个学生是否通过考试。假设我们有学生的学习时间数据,我们希望利用逻辑回归来预测通过考试的概率。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, log_loss, roc_curve, auc
# 生成示例数据:学习时间 (小时) 和是否通过考试 (0 = 未通过, 1 = 通过)
np.random.seed(42)
study_time = np.random.rand(100, 1) * 10 # 学习时间 0 到 10 小时
pass_exam = (study_time > 5).astype(int).ravel() # 学习时间超过5小时则通过考试,加上噪声
# 可视化数据
plt.scatter(study_time, pass_exam, color='blue', label='真实数据')
plt.xlabel('学习时间(小时)')
plt.ylabel('是否通过考试')
plt.title('学习时间与考试结果的关系')
plt.legend()
plt.show()
# 使用 sklearn 训练逻辑回归模型
model = LogisticRegression()
model.fit(study_time, pass_exam)
# 预测通过考试的概率
study_time_test = np.linspace(0, 10, 100).reshape(-1, 1)
exam_pass_prob = model.predict_proba(study_time_test)[:, 1] # 预测通过的概率
# 可视化预测结果
plt.scatter(study_time, pass_exam, color='blue', label='真实数据')
plt.plot(study_time_test, exam_pass_prob, color='red', label='预测通过概率')
plt.xlabel('学习时间(小时)')
plt.ylabel('通过考试的概率')
plt.title('逻辑回归预测')
plt.legend()
plt.show()
# 计算模型的准确率和交叉熵损失
y_pred = model.predict(study_time)
accuracy = accuracy_score(pass_exam, y_pred)
cross_entropy = log_loss(pass_exam, model.predict_proba(study_time))
print(f"模型准确率: {accuracy:.2f}")
print(f"交叉熵损失: {cross_entropy:.2f}")
# ROC 曲线和 AUC 值
fpr, tpr, _ = roc_curve(pass_exam, model.predict_proba(study_time)[:, 1])
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC 曲线')
plt.legend(loc="lower right")
plt.show()
代码分析
- 数据生成与可视化
- 模拟生成的“学习时间”和“是否通过考试”数据,超过 5 小时的学习时间更有可能通过考试,但包含一定噪声,以增加实际情况的复杂性。
- 逻辑回归模型训练
- 通过
LogisticRegression()创建模型实例,并使用model.fit进行训练,模型会学习到最优的 $w$ 和 $b$ 值,使得交叉熵损失最小。
- 通过
- 预测与可视化
- 使用
predict_proba预测学生通过考试的概率,并绘制 S 型曲线展示逻辑回归对概率的拟合。
- 使用
- 评估指标
- 使用 准确率(Accuracy) 评估模型的分类效果,并计算交叉熵损失,判断模型的拟合程度。
- ROC 曲线和 AUC 值展示模型的整体性能,AUC 越接近 1 表示模型效果越好。
小结与扩展
- 逻辑回归为何适合分类?
- 逻辑回归通过 Sigmoid 函数将输出映射为 0-1 之间的概率值,能很好地解决二分类问题,且对分类结果具有概率解释性。
- 交叉熵的优势
- 交叉熵在分类问题中表现出色,因为它会让模型在训练过程中“惩罚”错误的分类,使得模型输出概率更加贴近真实情况。
- 应用场景
- 逻辑回归不仅用于二分类,还可以用于多分类(通过扩展为 softmax 函数),在医疗诊断、金融欺诈检测等领域中有广泛应用。
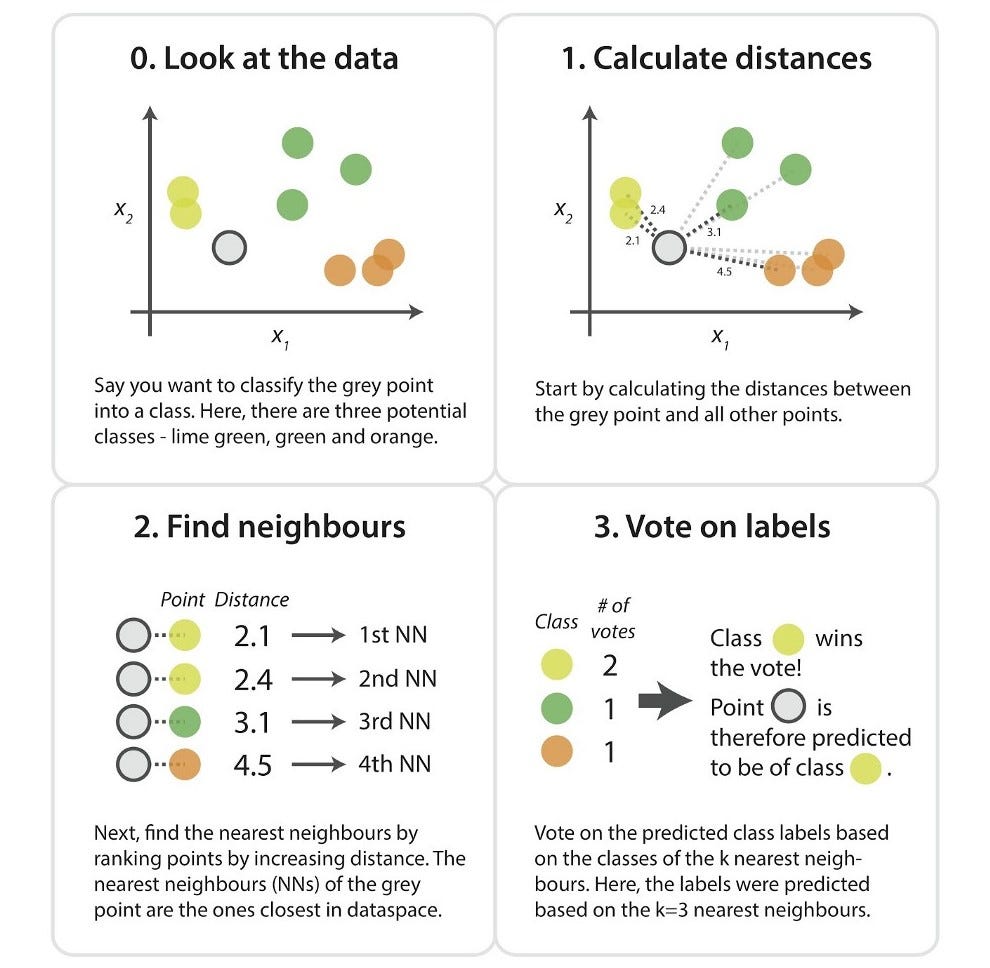
3. K近邻算法(KNN):一种“投票”分类方法
- 概念:K近邻是一种基于“投票”的分类算法。给定一个样本,它会查找最近的K个邻居,用多数投票法决定类别。
-
公式:使用欧氏距离公式来计算样本之间的距离:
\[d(x_i, x_j) = \sqrt{\sum_{k=1}^{n} (x_{i,k} - x_{j,k})^2}\]
代码示例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# 生成更复杂的示例数据
np.random.seed(42)
X = np.concatenate([np.random.rand(50, 2) * 5, np.random.rand(50, 2) * 5 + 5])
y = np.concatenate([np.zeros(50), np.ones(50)]) # 创建两个类别:0和1
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建并训练KNN模型
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("预测类别:", y_pred)
print("模型准确率:", accuracy)
# 可视化决策边界
def plot_decision_boundary(model, X, y, h=0.1, ax=None, title=""):
# 设置坐标轴范围
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 预测网格数据点
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界
if ax is None:
fig, ax = plt.subplots()
ax.contourf(xx, yy, Z, alpha=0.3, cmap='coolwarm')
ax.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', s=50, cmap='coolwarm')
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_title(title)
# 可视化训练集和测试集的决策边界
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
plot_decision_boundary(model, X_train, y_train, ax=axs[0], title="Training Set Decision Boundary")
plot_decision_boundary(model, X_test, y_test, ax=axs[1], title="Test Set Decision Boundary")
# 设置图像标签
axs[0].set_title("训练集决策边界")
axs[1].set_title("测试集决策边界")
plt.show()
# 比较不同k值的效果
k_values = [1, 3, 5, 7, 10]
accuracy_scores = []
for k in k_values:
model_k = KNeighborsClassifier(n_neighbors=k)
model_k.fit(X_train, y_train)
y_pred_k = model_k.predict(X_test)
accuracy_scores.append(accuracy_score(y_test, y_pred_k))
# 可视化k值与模型准确率的关系
plt.figure(figsize=(8, 6))
plt.plot(k_values, accuracy_scores, marker='o', linestyle='-')
plt.xlabel("k值 (邻居数)")
plt.ylabel("测试集准确率")
plt.title("不同k值下的KNN模型准确率")
plt.show()
四、模型评估与混淆矩阵
1. 混淆矩阵:用于描述分类模型的性能
-
TP(True Positive):预测为正,实际也为正。
-
TN(True Negative):预测为负,实际也为负。
-
FP(False Positive):预测为正,但实际为负。
-
FN(False Negative):预测为负,但实际为正。
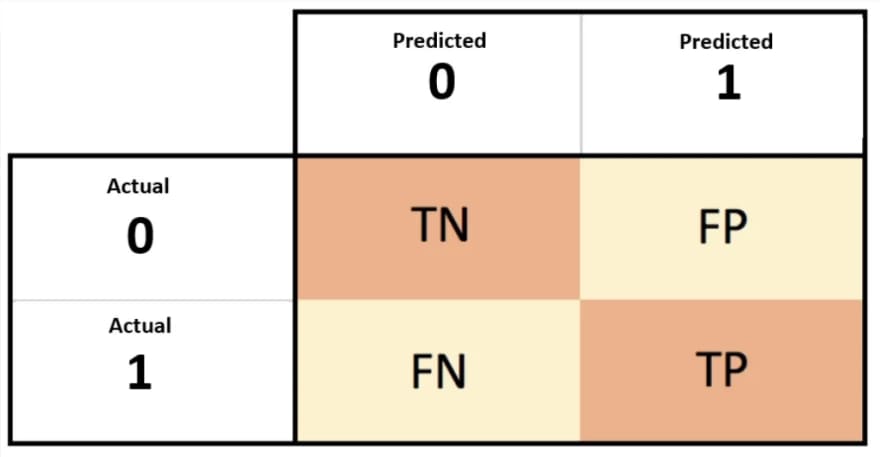
2. 评估指标
-
准确率(Accuracy):所有正确预测的比例
\[Accuracy = \frac{TP + TN}{TP + TN + FP + FN}\] -
精确率(Precision):预测为正中,真正的比例
\[Precision = \frac{TP}{TP + FP}\] -
召回率(Recall):实际为正中,被正确预测的比例
\[Recall = \frac{TP}{TP + FN}\]
代码示例:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix, precision_score, recall_score
# 示例真实标签和预测标签
y_true = [0, 0, 1, 1, 1]
y_pred = [0, 1, 1, 0, 1]
# 计算混淆矩阵和指标
conf_matrix = confusion_matrix(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
print("混淆矩阵:\n", conf_matrix)
print("精确率:", precision)
print("召回率:", recall)
# 使用matplotlib和seaborn可视化混淆矩阵
plt.figure(figsize=(6, 4))
sns.heatmap(conf_matrix, annot=True, fmt="d", cmap="Blues", cbar=False)
plt.xlabel("预测标签")
plt.ylabel("真实标签")
plt.title("混淆矩阵可视化")
plt.show()
总结
今天的内容主要是:机器学习的流程、损失函数、常见模型及其应用场景。希望大家在未来的学习中能进一步理解和应用机器学习!